
SOAR : Quelles conclusions en 2020 ?

Le CyberSOC présente ici un retour d’expérience sur les solutions SOAR, tant sur nos usages internes que ceux observés chez nos premiers clients.
Depuis 2016, les acronymes SIRP (Security Incident Response Platform), puis SOAR (Security Orchestration Automation Response) font parler d’eux. Entre temps, des projets d’intégration se sont initiés et le marché s’est consolidé avec notamment quelques acquisitions marquantes :
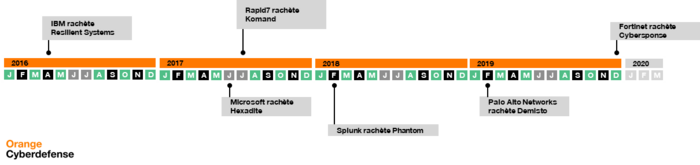
Figure 1 – Acquisitions marquantes des solutions SOAR – Source : Orange Cyberdefense
Si, aujourd’hui, l’utilité d’un tel outil n’est plus à prouver, il est cependant important de faire le bilan et de dresser un état des lieux en ce début d’année 2020. Nous allons donc, au sein de cet article, partager un retour d’expérience sur les solutions SOAR, tant sur nos usages internes que ceux observés chez nos premiers clients ayant entamé un projet d’intégration.
SOAR : état des lieux et analyse
Il est clair qu’aujourd’hui les clients les plus matures sur les questions de cybersécurité ont déjà entrepris des premières réflexions, voire déjà déployé une solution SOAR. Les grandes organisations et MSSP (Managed Security Service Provider) sont ainsi les plus concernés face à ce besoin d’automatisation et d’industrialisation du traitement des incidents. Il est évident qu’une organisation plus modeste sur le point de vue de la sécurité orientera plutôt sa stratégie vers d’autres priorités comme la détection.
Dans ce contexte, est-ce qu’une organisation peut et doit s’équiper d’un SOAR dès la création de son SOC (Security Operation Center) ? Certaines entreprises ont effectivement fait le choix de déployer le package complet : SIEM (Security Information and Event Management) + SOAR. Ces projets sont ambitieux, la marche est haute, mais avec du conseil, de l’assistance et une forte implication des équipes, c’est en réalité tout à fait possible, mais loin d’être un facteur de succès du SOC.
En termes de déploiement, Gartner a publié en février 2018 l’étude intitulée Preparing Your Security Operations for Orchestration and Automation Tools[1] mentionnant des délais d’intégration allant de 6 à 9 mois. Les chiffres sont assez proches de ce que nous avons pu observer, tout en gardant à l’esprit que, comme la majorité des scénarios et règles de détection des SIEM, les worflows (ou playbooks) sont par la suite en constante amélioration.
En termes de cas d’usage, l’automatisation du traitement des mails malveillants collectés depuis une boîte mail type abuse semble être la plus fréquente avec un grand nombre de déploiements chez nos clients, ainsi qu’un bon ratio de tâches chronophages automatisées. Le parsing et l’extraction automatique des artifacts ainsi que leur enrichissement (Whois, enregistrement DNS, information des certificats HTTPS, etc.) vient en premier. Suit une analyse plus au moins poussée du mail, avec notamment la comparaison des indicateurs avec des bases de Threat Intelligence et la détonation des fichiers et URL vers une sandbox. Certaines organisations ont d’ailleurs pris une certaine avance avec l’application de plusieurs outils supplémentaires permettant, entre autres, de fournir une analyse plus approfondie : distance de Levenshtein, pattern/text matching, analyse d’image (OCR, détection de logos, etc.), mais également des algorithmes de machine learning, qui viennent compléter les bases de connaissances souvent insuffisantes pour détecter les attaques plus avancées ou ciblées.
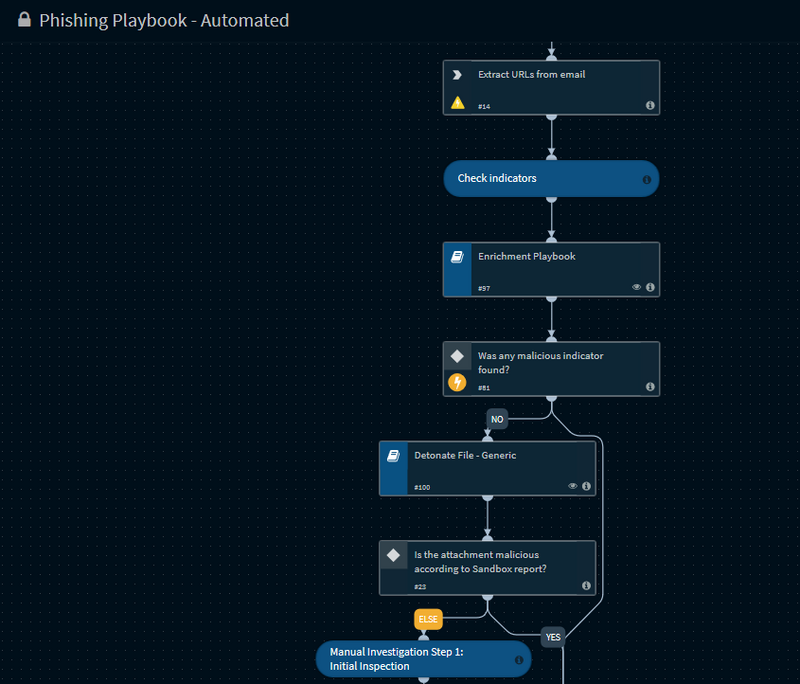
Figure 2 – Phishing Playbook automated (extract) – Source : Demisto
Viennent ensuite les playbooks plus génériques, de triage et de qualification des incidents. Ici, nous retrouvons majoritairement en sources, un SIEM, ou plus simplement un EDR (Endpoint detection and response) ou des sondes réseaux, qui remonteront des alertes et qui seront ensuite collectées, “mappées”, puis enrichies par diverses intégrations (Active Directory, Threat Intelligence, CMDB ou Configuration Management Database, etc.). Assignations, notifications et gestion des SLA (Service Level Agreements) font souvent partie de ce premier playbook générique.

Figure 3 : industrialisation du triage et de qualification des incidents. Source : Orange Cyberdefense CyberSOC
Chez de grandes organisations disposant généralement d’un CERT et/ou d’un CSIRT fournissant des indicateurs de compromission ciblés, nous avons également retrouvé un cas d’usage assez présent : la recherche d’indicateurs sur un parc. Depuis une instance MISP (Malware Information Sharing Platform), ils sont envoyés depuis un mail, un fichier CSV, ou un simple indicateur : la capacité à interroger rapidement des équipements type SIEM, log management, EDR ou NTA (Network Traffic Analysis) afin d’identifier si un indicateur a été observé sur un parc est également portée par le SOAR.
L’intérêt est réel car aujourd’hui la majorité des indicateurs de compromission est déployée au sein des SIEM pour une détection en temps-réel, mais ils ne sont pas recherchés sur une période antérieure.
Nous détecterons donc une compromission future, mais pas passée. Pourquoi ? Un bon nombre d’attaques sont mutables ou ponctuelles, par exemple, les phishings ou infections par des malwares de type stealers permettent une exfiltration des credentials. Sans recherche historique, cette compromission n’aurait donc jamais été identifiée. Nul doute que les précédentes campagnes de ransomwares ont également poussé un bon nombre d’entreprises à développer leur capacité de recherche de compromission.
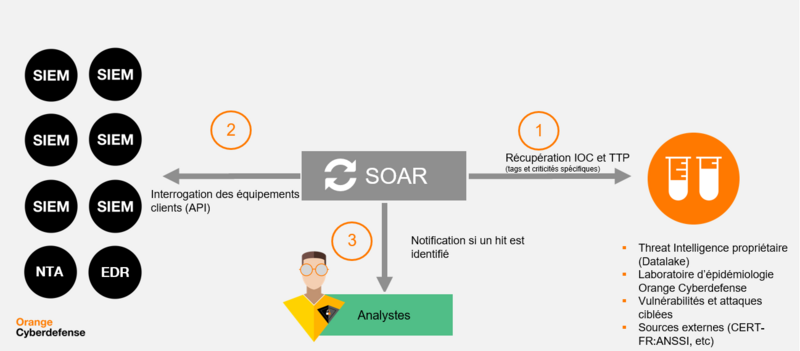
Figure 4 – Fonctionnement retro-hunting. Source : Orange Cyberdefense
Outre l’aspect générique, évidemment, des playbooks de réponses à incidents plus spécifiques sont déployés. En priorité, le traitement des incidents de type malware, qui peut être décliné par types (ransomware, vers, Trojan, etc.), voire familles (Emotet, Nanocore, Azorult, etc.). Le triage, l’enrichissement et la qualification étant en partie automatisés en amont, le travail est ici plus centré sur l’analyste avec des tâches manuelles à forte valeur ajoutée.
Les playbooks de réponses à incidents de type emails malveillants sont également largement déployés avec des spécificités par famille : phishing, spear phishing, fraudes au président et bien d’autres.
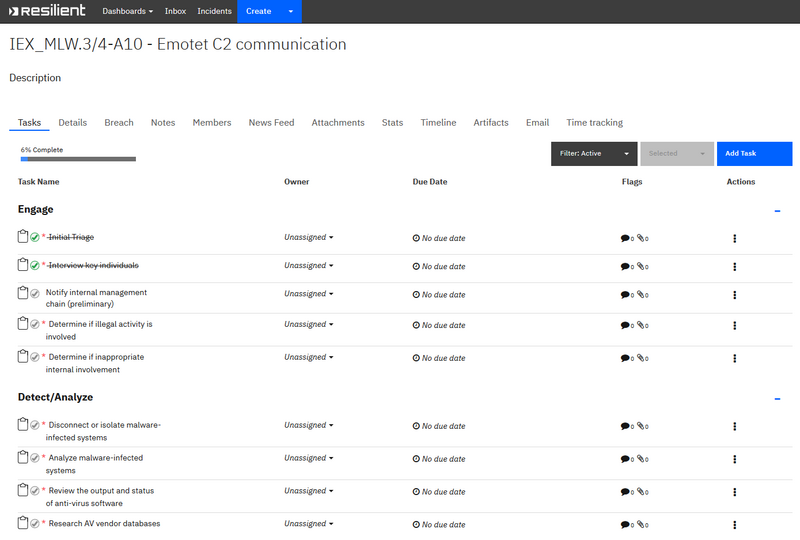
Figure 5- Playbook d’investigation Malware (extract). Source : IBM Resilient
L’automatisation des processus de remédiation n’est encore que très peu déployée. Bien que techniquement possible (déploiement d’une blacklist sur un proxy/firewall, isolation d’un poste/serveur depuis un EDR, suppression d’emails dans des boîtes aux lettres via Office 365, etc.), les organisations préfèrent encore privilégier une réalisation manuelle.
Soit les équipes en charge ont directement un accès à la solution et une tâche leur sera assignée, soit le SOAR s’occupe de créer automatiquement un ticket vers un outil tiers tel qu’un ITSM (IT Service management). Une bonne connaissance des risques et un référentiel à jour permettant d’identifier les serveurs critiques, VIP, administrateurs sont nécessaires pour éviter ou limiter au maximum les dommages collatéraux. Un arbre de décisions pourra être ensuite construit en fonction des informations récoltées.
Certes, nous retrouvons de nos jours certains cas d’usage massivement déployés, mais il existe cependant des besoins bien différents pour chaque métier. Un MSSP, n’ayant pas toujours les accès d’administration chez son client, orientera son usage sur des playbooks d’investigation et accordera une grande importance aux aspects collaboratifs, à la capitalisation et à la base de connaissances. Une organisation disposant de son propre SOC aura quant à elle des accès plus étendus et pourra ainsi étendre la contextualisation, la remédiation, mais aussi le développement de playbooks pour l’IT et les métiers.
SOAR : quelles sont les difficultés rencontrées ?
Bien que paradoxale, la première difficulté observée semble être la gestion des ressources humaines. Les solutions étant rarement plug-and-play et face à la réalité du manque de compétences en sécurité informatique, les déploiements sont beaucoup plus complexes et chronophages que prévus. Un retour sur investissement clairement quantifiable est donc rarement atteint lors des premiers mois d’un tel projet.
Les capacités d’automatisation et d’intégration riment souvent avec développement, ce qui implique bien sûr des compétences spécifiques, un modèle opérationnel, voire une équipe dédiée dans le cas où des playbooks ou connecteurs complexes seraient développés en interne. De plus, les intégrations avec des outils ou solutions tiers impliquent une multitude d’équipes hétérogènes au sein du projet, certaines pouvant être très sceptiques à l’idée qu’un outil puisse réaliser des actions potentiellement dommageables, et ce, de façon automatique. Bien évidemment, des fonctionnalités de bridage ou de validation de ces types d’actions sont disponibles, mais cela ne suffit pas toujours à convaincre.
L’adaptation au changement est également une difficulté pour les équipes. Les interfaces étant parfois complexes à appréhender au premier abord, elles ne sont maîtrisées qu’après quelques jours, voire semaines d’utilisation. Le changement le plus notable est sûrement pour les équipes de niveau 1, qui sont autant impactées par l’arrivée d’un nouvel outil que par l’automatisation d’une grande partie du processus de triage et de qualification. En prenant en compte le turnover des équipes, la formation sur ces nouveaux outils est donc une vraie problématique du fait de son rôle central.
Sous le discours marketing prometteur, se cache donc une réelle complexité et certaines organisations n’ont pas encore acquis la maturité nécessaire pour entreprendre le déploiement d’un SOAR. Les processus de traitement des incidents de sécurité ne sont souvent que partiellement maîtrisés et documentés, et sans ces informations contextuelles essentielles, aucune automatisation n’est envisageable.
Nos conseils avant d’entreprendre un projet de SOAR
Gouvernance et gestion de projet
Comme mentionné en introduction, les projets sont longs et impliquent de nombreuses équipes. L’aspect gouvernance et gestion de projet n’est donc pas à négliger. La validation des prérequis techniques, qui impliquent beaucoup d’ouverture de flux et de création de comptes de services ou API (Application Programming Interface), ainsi que la mobilisation des équipes peuvent être des risques notables. N’oublions pas que les organisations les plus à même de s’équiper d’un SOAR sont loin du modèle de la start-up. Les processus complexes et des fonctionnements en silos sont de réels freins, d’autant plus que les équipes ont parfois des objectifs très différents, voire contradictoires.
La définition d’un modèle opérationnel cible est une réflexion à avoir : qui s’occupe de la création et de l’amélioration des playbooks ? Une nouvelle équipe dédiée ou les équipes du SOC ? La même question doit être posée pour la définition des processus, le développement et le maintien des intégrations, ainsi que pour la plateforme. Il est certain que des méthodes de gestion de projet spécifiques au monde du développement ont ici leur place et doivent être envisagées.
SOAR : processus connus et maîtrisés
Les processus de réponses à incidents ne sont que trop peu documentés aujourd’hui. Il est essentiel qu’ils soient connus, maîtrisés, mais surtout fiabilisés et contextualisés.
Des bases existent bien : SANS, NIST et même des CERT, comme le CERT SG[2], partagent leurs fiches et méthodologies de réponses à incidents. Des solutions embarquent également des templates de playbooks et workflows. Certes, ces documents et templates sont de très bons points de départ, mais la contextualisation n’est surtout pas à négliger et un accompagnement sur la définition et l’amélioration des processus de réponses à incidents est judicieux dans certains cas. La norme BPMN (Business Process Model and Notation[3]) semble faire l’unanimité car un grand nombre d’éditeurs s’appuie sur ce standard pour la modélisation des playbooks.
Une documentation des processus de réponses à incidents en amont permet également d’optimiser leur représentation en identifiant les phases similaires ou identiques présentes dans plusieurs cas d’usages. Par exemple, la gestion d’un compte compromis, que ce soit à la suite d’une infection par un malware, ou via un phishing, le processus sera sensiblement le même dans la plupart des organisations. Ainsi, sur certaines solutions permettant la création de “sous-playbooks“, la réutilisation de sous-blocs rendra l’intégration et l’évolution des playbooks beaucoup plus simple.
Un fonctionnement en mode dégradé est également à considérer. Comment fonctionner si la solution SOAR est indisponible ? L’utilité de préparer ces processus de réponses, documentés et accessibles rapidement, permet de garder un fonctionnement du SOC acceptable, malgré une dégradation du service.
SOAR : la priorisation
L’erreur de vouloir, dès le début, automatiser une trop grande partie des processus de réponses à incidents est souvent faite par les entreprises. La meilleure approche serait plutôt de déployer des playbooks exclusivement manuels dans un premier temps, puis, en fonctionnant par itération, d’automatiser les tâches les plus répétitives et chronophages en priorité.
Cette méthode permet d’avoir rapidement une solution opérationnelle, mais également de pouvoir calculer un retour sur investissement très facilement. L’adhésion à ce type d’outils est ainsi plus naturelle pour les équipes d’analystes.
Il est également préférable de se concentrer sur la préparation et la qualité au nombre de playbooks intégrés. Nous recommandons de commencer par identifier un nombre de cas d’usage limité, cartographier les équipements et solutions qui seront utilisés, déterminer les informations pertinentes pour votre organisation et vos équipes opérationnelles, ce qui vous permettra de créer, d’alimenter, et “mapper” des champs spécifiques à votre organisation. Viendront ensuite la définition des métriques et KPI à intégrer par la suite. Un cahier de recettes peut permettre de valider la chaîne complète de déploiement.
Conclusion
En tant que MSSP et utilisateur de SOAR, nous avons un réel devoir de conseil et d’accompagnement de nos clients qui s’interrogent aujourd’hui sur l’utilité et la complexité d’un tel outil. Les éditeurs ont également une carte à jouer afin de proposer des produits réellement clés-en-main avec des modèles simples comme des solutions SaaS (software as a service), qui pourront ainsi faciliter l’adoption des organisations moins matures, tout en leur offrant un retour sur investissement intéressant. C’est d’ailleurs l’approche des solutions comme Azure Sentinel de Microsoft et InsightIDR/Connect de Rapid7 qui mettent à disposition des solutions SOAR directement intégrés à leurs solutions SIEM SaaS. Certes moins évoluées que les pures players, ces solutions fournissent cependant des fonctionnalités suffisantes pour une majorité de SOC.
En plus des éditeurs et fournisseurs de services, les communautés d’utilisateurs semblent également jouer un rôle important et un nombre d’éditeurs utilisent cet argument marketing. Version gratuite, mais limitée, partage du code des intégrations, de playbooks, les solutions mettant à disposition des contenus, par exemple sur un dépôt GitHub facilitent donc le partage et la participation de la communauté. La solution Demisto a par exemple bien compris cet intérêt, et met ainsi à disposition un dépôt Github et un channel Slack pour sa communauté.
Nous sommes encore au début du SOAR, Gartner indiquait en ce sens que d’ici 2022, 30% des organisations disposant d’une équipe d’au moins cinq personnes vont s’équiper d’un SOAR, contre moins de 5% en 2019. Les prochaines années s’annoncent donc déterminantes pour ces solutions et ces trois acteurs (MSSP, éditeurs et communautés) auront un rôle crucial.
[1] Gartner, Preparing Your Security Operations for Orchestration and Automation Tools https://www.gartner.com/en/documents/3860563
[2] CERT Societe Generale, IRM (Incident Response Methodologies): https://github.com/certsocietegenerale/IRM
NIST, Computer Security Incident Handling Guide
https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf
SANS, Incident Handler’s Handbook
https://www.sans.org/reading-room/whitepapers/incident/incident-handlers-handbook-33901
[3] Wikipedia, BPMN : https://fr.wikipedia.org/wiki/Business_process_model_and_notation


