
The Nutanix Metro Availability Solution, for private cloud
Recently, I have been given the opportunity to compare the different features of the Nutanix Metro Solution. We were given two Nutanix blocks by our Nutanix System Reliability Engineer (SRE) which allowed us to take a deep dive into the various configurations.
Some of our customers already had the Nutanix Metro Setup in their datacenter, even before the announcement of the Metro Availability Witness. That is why we wanted to compare both setups in order to discover the added value of a witness VM within a Nutanix Metro Cluster.
A brief history on Metro Availability
Metro Availability was released with AOS 4.1 back in 2015. The goal of this solution was to reduce the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) to nearly zero.
Back in 2015, this RPO rate was actually achieved, but in a disaster scenario, a manual intervention was needed which determined the RTO time.
The Announcement of a Witness
On the 3d of January 2017, Nutanix released AOS 5.0 and from this release on, it was possible to set up a light-weight service that was able to run anywhere to the automated failover from one site to another without human interaction.
Nutanix Witness VM Setup Requirements
The Witness VM runs as a standalone virtual machine and is available in two versions: VMware ESX or AHV.
Hardware requirements of the witness VM are:
- At least 2 vCPUs
- A minimum of 6 GB of memory
- 25GB of storage
An important site level requirement is to have two individual and independent network connections with a round trip latency (RTL) < 200ms.
Nutanix Clusters: Lab Setup
To filter out as many variables that could alter our test results as possible, we used intermediate devices which were not connected anywhere but between the Nutanix test clusters. This ensured a fully isolated test environment. Both Nutanix clusters had the exact same switch type FlexFabric 5700-32XGT-8XG-2QSFP+.
To simulate all various network outages, we used a Palo Alto PA-3050 where we could drop connections between the clusters and witness by virtually cutting the wires between sites.
On each user virtual machine (UVM) that we powered on, we configured an I/O performance tester to monitor the in-guest I/O’s from and to the hypervisor/CVMs.
Logical display Lab setup

Summarized results of the comparison
One of the first highlights of our comparison is that there are no major I/O stun differences between both setups. Which implied that no disadvantages where monitored between the cluster and the actual workload.
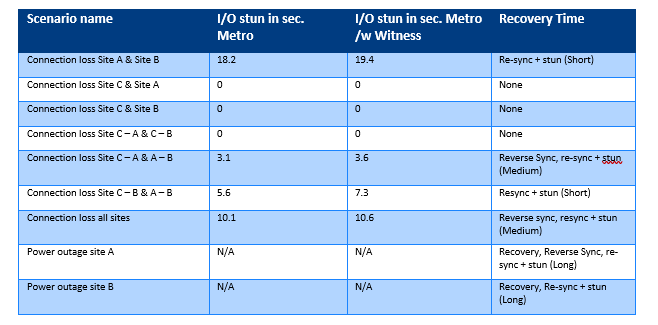
From a business continuity point of view, we noticed that the Metro, combined with Witness, has many potentials to reduce the recovery time objective (RTO) drastically.
What the witness basically does is performing the promotion of the metro container at the ‘surviving’ site in an automated manner. The clusters high-availability mechanism (HA) will spin up an all failed virtual machine in the far-end cluster ensuring business continuity with minimal impact and RTO.
One mentionable item is that when you need to recover from a site failure, you have to reverse the synchronization direction, which causes a stun in I/O. When failing back to your primary site, this will also have an additional I/O stun. But if you put this in perspective, it is a minor issue.
If your business requires a solution that provides enterprise-upclass uptime, the extended feature of the Nutanix Metro cluster combined with a Witness VM will definitely meet your needs.
Do you have a question about this topic or would you like more information? Please do not hesitate to ask us!