
Part 3 - Forging forward with GenAI

Introduction
We will provide a very high-level overview of what is involved in creating large language models (LLMs), an amazing technology. By pulling back the curtain we reveal some of the inner workings that can help you appreciate the complexity and sophistication required to build and maintain an LLM. This blog is to serve as a basic primer and it is not intended as a “howto” or a recipe for emulating what OpenAI, Google Gemini, xAI, and the like are doing.
As a reminder: An LLM is a breakthrough in natural language processing (NLP) and machine learning (ML), a subset of artificial intelligence (AI), that enables a machine to interact with humans using various forms of human language.1 2
The machine can “understand” requests or instructions and respond in a way that seems very human displaying various traits we normally do not ascribe to machines.
This is the start of the second chapter in a series of blog posts on Generative AI (GenAI). Here are part 1 and part 2 of the first chapter
Hard requirements
There is a strong correlation between the volume of data used to train the models on and the skills and infrastructure that supports this effort. Building world class LLMs requires skilled staff with expertise in data science, machine learning, highspeed parallel computing, large datacenter and infrastructure management, and many more other technical and non-technical skills.
It is possible to build a model using consumer grade hardware, but there will be a hard cap on the capabilities of the produced LLM. This type of approach is good for educational purposes and rough prototyping, but the final utility will be limited.
An alternate approach is to rent computing power from cloud providers or dedicated AI service providers, but this will still have a limiting effect on the final model’s capability compared to what others with dedicated high-end infrastructure can produce.
For our discussion, know that you require multiple pieces of hardware modules such as graphic cards that can perform specialized parallel computation and a lot of communication bandwidth between these hardware modules. Also, you will require ample reliable and fast storage space.
Steps of building an LLM
In this series of discussions we will touch on three phases that are conceptually necessary to produce an LLM. This will be an oversimplification of a real-world process. There are broadly speaking three steps:
- Pre-training
- Producing a base model (covered in the next blog post)
- Post-training (covered in the next blog post)
What is amazing about the LLM ecosystem today is the existence of open-source or open weight models. Also, the ecosystem is built around a well-defined set of tooling that is freely available, such as PyTorch. This allows users to skip the first two steps mentioned here and go straight into customizing the LLM in the post-training phase. This lowers the barrier to entry, allowing people to customize a model to their liking. This does however require understanding of the earlier steps as it could still result in an LLM with undesirable properties. For an example of customized LLMs visit the Hugging Face project.
Pre-training
This initial step consists of several dependent activities. Data is required to train the model, and the quality and quantity of the training dataset plays an important role in what the model is capable of. This will require a process that crawls the web downloading content. This collected data must be “cleaned” to eliminate unwanted content, duplicate content, exclude copyright material, include only specific language such as English, etc.
This prepared dataset is converted into a special encoding called tokenization. This “translates” words and common character sequences into numerical representations, resulting in an array of numbers. A special tokenization algorithm called embeddings is used to represent the semantic relationships between tokens, thus providing context.
Finally, we arrive at the model training step. This will require the configuration and setup of the algorithm that will be responsible for creating the model. The algorithm, also referred to as a neural network, is a complex process that involves chaining several components that perform calculations to determine special values called weights. These weights are what gives the LLM its features in how the LLM generates responses to user input.
The model will be evaluated to determine if it is fit for purpose, else adjustments are made and then the model is passed through another training iteration. The pre-training step stops when the model meets certain requirements, and this will result in the base model.
Data collection
Large language models (LLMs) require data and a lot of it. The easiest source of data is to scour the Internet and download as much as possible. Companies such as OpenAI and Anthropic state publicly their crawling process to be as transparent as possible.3 4 However there are others that act inconsiderately by hoovering up what they can find. This is taking its toll on smaller businesses that are struggling with what is almost a daily distributed denial of service attack (DDoS) as the crawlers’ resources out strip that of the web properties they query.5
Some individuals and vendors are fighting back against this onslaught by AI scrapers. One example is a project called Anubis by Xe Iaso that blocks access if the visitor is unable to perform a special computation.6 The mitigation imposes a requirement on the visitor to the site protected by Anubis. The web browser must perform a “proof of work” task that is only possible in modern web browsers. This proof of work comes in the form of a special JavaScript program that can compute a value that Anubis expects. The AI scrapers on the other hand do not have the ability to execute the Anubis proof of work JavaScript, and subsequently they are blocked.
Cloudflare takes a different approach with their AI Labyrinth mitigation that sends AI scrapers into a maze of “fake” web content. When AI Labyrinth detects a data scraper, they generate content and serve it to the data scraper with links to more “fake” content. This effectively puts the data scraper on a path to nowhere keeping it busy collecting nonsense thus poisoning the collected data set.7
If you go about hoovering up the internet, then be conscious about what data is being collected and how aggressive this process is. Respect the various industry standards that apply to web crawlers and their acceptable use.8
3 https://platform.openai.com/docs/bots
4 https://support.anthropic.com/en/articles/8896518-does-anthropic-crawl-data-from-the-web-and-how-can-site-owners-block-the-crawler
5 https://drewdevault.com/2025/03/17/2025-03-17-Stop-externalizing-your-costs-on-me.html
6 https://xeiaso.net/blog/2025/anubis/
7 https://arstechnica.com/ai/2025/03/cloudflare-turns-ai-against-itself-with-endless-maze-of-irrelevant-facts/
8 https://www.robotstxt.org/
Fast tracking data collection
The Hugging Face artificial intelligence (AI) platform provides guidance on how to go about data collection as described by their FineWeb project that derives its dataset from the not for profit Common Crawl project.9 10 The FineWeb dataset already contains much of the internet and it is already tokenized ready for training.11 The FineWeb dataset consists of 15-trillion tokens and consumes approximately 44 terabytes of disk space.
This 15-trillion token dataset was built using 96 snapshots of the Common Crawl snapshots. FineWeb version 1.3.0 is dated 31 January 2025 and complies to Cease and Desist orders to exclude certain domains from the dataset.12 This is to respect copyright claims and to comply with specific legal and compliance rulings. Another important point to note is that FineWeb explicitly attempts to remove personal identifiable information (PII) from the Common Crawl dataset. Additionally, the FineWeb dataset is released under the Open Data Commons Attribution License (ODC-By) v1.0.13
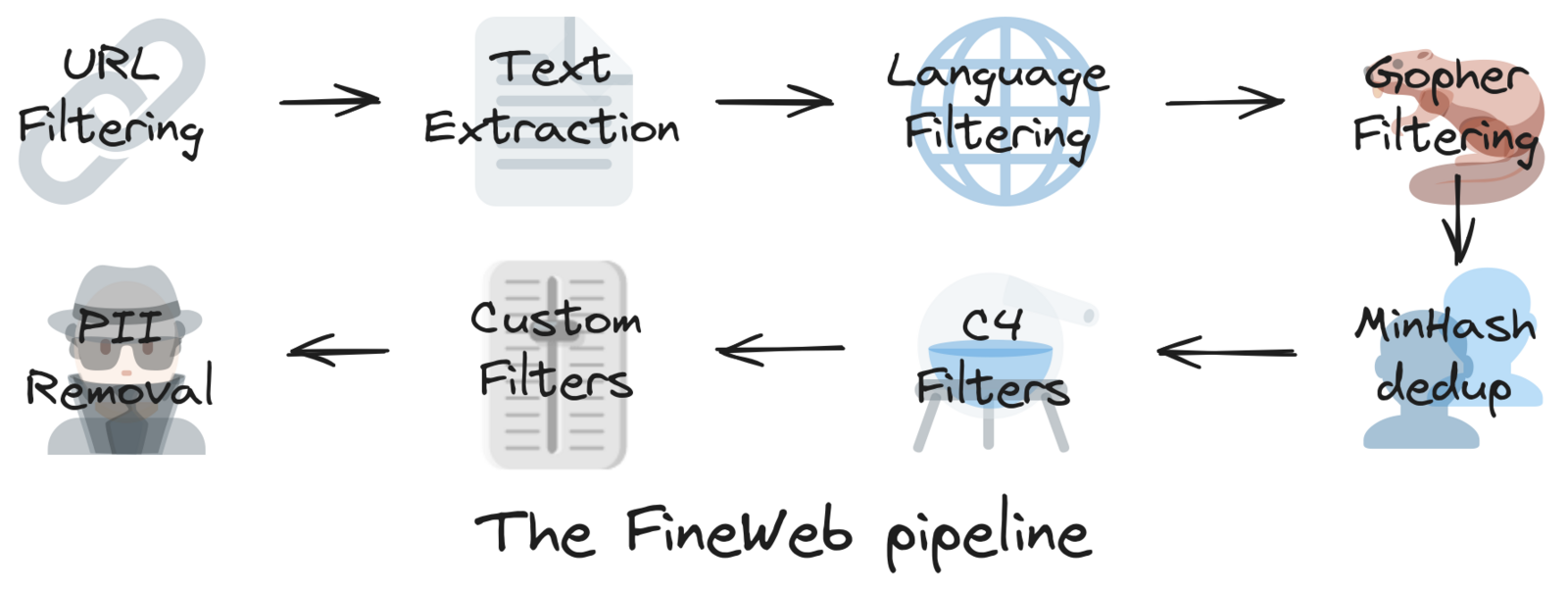
This is yet another reason why using a curated dataset such as FineWeb can help you start clean, by establishing provenance of the data that you are using to train your models with. This kind of transparency will become necessary as the supply chain becomes busier, as well as anticipating future compliance and laws of various jurisdictions. Some clients might require proof that laws were respected during the data collection and preparation process.
9 https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
10 https://commoncrawl.org/
11 https://huggingface.co/datasets/HuggingFaceFW/fineweb
12 https://huggingface.co/datasets/huggingface-legal/takedown-notices/blob/main/2025/2025-01-22-Torstar.md
13 https://opendatacommons.org/licenses/by/1-0/
Tokenization
Tokenization is a natural language processing (NLP) approach that converts text into a numerical representation.14 This numerical representation or encoding is reversable, meaning that we can take a token sequence and instantiate the character sequences representing words or other meaningful output.
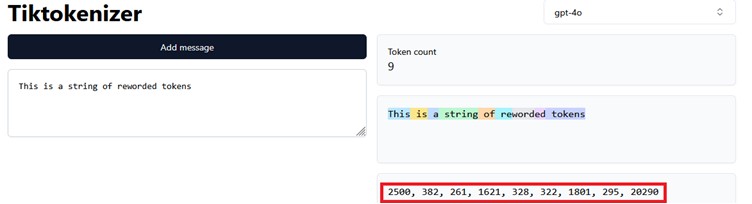
Here is a visualization of tokenization using the Tiktokenizer webapp. In the example we are using the GPT-4o tokenizer algorithm, and it has a vocabulary size of 199,997 tokens or symbolic representations. 15 16 The sentence “This is a string of reworded tokens” is encoded into 9 tokens or numbers highlighted in the red rectangle. The mapping is thus:
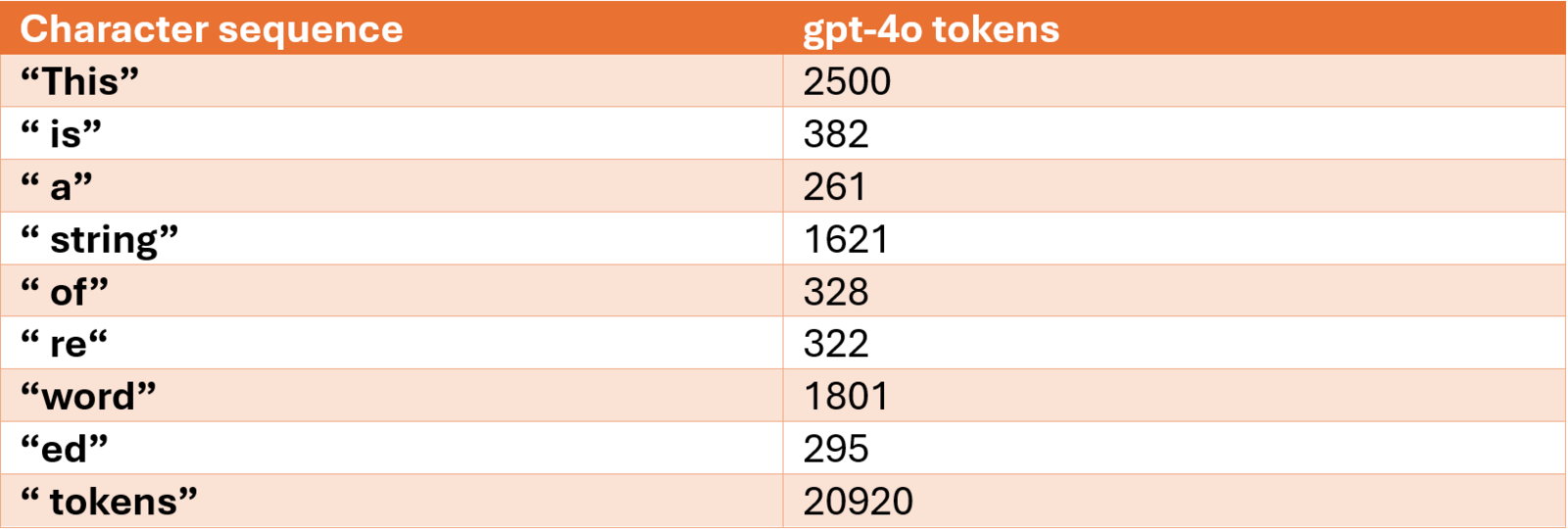
NOTE: The double quotes are introduced to illustrate the leading space character for all the words except the first. The double quotes are not part of the mapping or sequence.
For every occurrence of the character sequence “ is” or “ a” there will be token/number 382 or 261 to represent the respective character sequence. Certain character sequences are split into more than one token, for example “reworded” is encoded to tokens 322, 1801, and 295. This technique is known as subword tokenization and is used to represent less commonly used character sequences. Also, this allows for smaller vocabularies since the tokenization does not have to create a unique mapping for each word or character sequence. The benefit is that it makes training or execution of LLMs much more efficient.
Other examples of tokenization include word tokenization, character tokenization, byte pair encoding (BPE), WordPiece tokenization, and unigram tokenization. 17 18
14 https://www.grammarly.com/blog/ai/what-is-tokenization/
15 https://arxiv.org/html/2406.11214v2
16 https://sebastianraschka.com/blog/2025/bpe-from-scratch.html
17 https://www.datacamp.com/blog/what-is-tokenization
18 https://tokenova.co/tokenization-in-nlp/
Embeddings
Embeddings is an important part of natural language processing (NLP) and is considered the semantic backbone of LLMs.19 Embeddings is a special tokenization representation that uses high-dimensional vector space to represent semantic relationships mathematically.
Several types of embedding algorithms exist such as Term Frequency-Inverse Document Frequency (TF-IDF), Word2Vec, BERT, etc. These approaches to creating embeddings can be used in various NLP tasks. In the case of LLMs the embedding is part of the input layer of a neural network and is updated during the training step. An embedding captures the contextual relationship between tokens to allow the LLM to predict the next token based on the preceding tokens.
The embedding vector size is dependent on the transformer model and impacts accuracy and performance. OpenAI’s GPT-2 has an embedding size of 768, while DeepSeek V3 has an embedding size of 7,168.20 21
Embeddings is such an important part of an LLM that this feature is offered as a special API that specializes in providing custom embedding capabilities that are optimized for certain industries and deployments.22 This is another example of where using other services can help improve or speed up your GenAI journey.
19 https://huggingface.co/spaces/hesamation/primer-llm-embedding?section=dimensionality
20 https://www.alignmentforum.org/posts/BMghmAxYxeSdAteDc/an-exploration-of-gpt-2-s-embedding-weights
21 https://mccormickml.com/2025/02/12/the-inner-workings-of-deep-seek-v3/#:~:text=embedding%20size
22 https://docs.anthropic.com/en/docs/build-with-claude/embeddings
Neural networks
A neural network is a statistical model that can predict the next token given a list of tokens as input. A neural network can consist of many layers of interconnected nodes that are a simplification of neurons and synapses found in human biology.23 This results in a complex mathematical structure that consists of parameters that were calculated during the training exercise and values of these parameters are referred to as weights.24 25
These weights are numerical values that are associated with the various connections between nodes or neurons at each layer.
The design of the mathematical equations that represent the neural network must be expressive and conducive to optimizations such being executed in parallel over multiple clusters of hardware. This allows for scalability and ensures that the training process can be improved by adding more hardware or interlacing various algorithms.
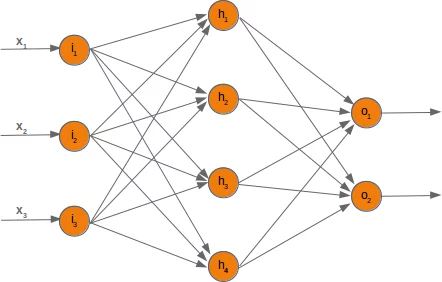
In Figure 3 we see the input layer (i) on the left, the hidden layer (h) in the middle, and the output layer (o) on the right. Note that the hidden layer can consist of many layers, and this is especially true for LLMs that generate output such as text, images, sound, etc.
OpenAI’s GPT-2 paper acted as a benchmark for defining generative LLMs.28 A generative pretrained transformer (GPT) is a specialized neural network that leverages several breakthroughs in neural network design and composition of which the transformer architecture is most recent and prominent.29 30 In addition, several other breakthroughs were instrumental to the architecture of GPTs and introduced concepts such as multilayered perceptron (MLP), recurrent neural networks (RNNs) to generate text, long-short term memory (LSTM), gated recurrent unit (GRU), feed forward deep convolutional neural networks (CNNs), and many others. 31 32 33 34 35 36
There are several configuration items that define features of the neural network, and these variables are called hyperparameters.37 The hyperparameters are set by the model creators during the training phase. Selecting the correct hyperparameters may require several diagnostic processes to sample values to determine the optimal hyperparameter values.
Another important feature of an LLM is the context window as this represents a segment of text, represented as a list of tokens, used by the LLM.38 The context window must be large enough to give the LLM a good chance of predicting the next sequence of tokens without being too computationally intensive. A typical context window can range from 128,000 (GPT-4) tokens up to 2 million tokens (Google Gemini 1.5 Pro). These context window limits are required by the transformer layer of the LLM.39
For example, if we feed the neural network a list of tokens for example “2500, 382, 261, 1621, 328, 322, 1801, 295” then we expect that it will predict the next token value of “20920”, resulting in the decoded character sequence of “This is a string of reworded tokens”. To predict the next token a model must be created that knows what the statistical chance is that the best or most likely next token is “20920” or word equivalent of “tokens”.
Here is an interactive depiction of a generative LLM that visualizes how the transformer architecture works step by step.
23 https://deepai.org/machine-learning-glossary-and-terms/weight-artificial-neural-network
24 https://deepai.org/machine-learning-glossary-and-terms/neural-network
25 https://python-course.eu/machine-learning/neural-networks-structure-weights-and-matrices.php
26 https://python-course.eu/images/machine-learning/example_network_3_4_2_without_bias.webp
27 https://deepai.org/machine-learning-glossary-and-terms/feed-forward-neural-network
28 https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdfù
29 https://arxiv.org/abs/1706.03762
30 https://poloclub.github.io/transformer-explainer/
31 https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
32 https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
33 https://www.cs.toronto.edu/~jmartens/docs/RNN_Language.pdf
34 https://arxiv.org/abs/1308.0850
35 https://arxiv.org/abs/1409.1259
36 https://arxiv.org/pdf/1609.03499
37 https://deepai.org/machine-learning-glossary-and-terms/hyperparameter
38 https://dataconomy.com/2025/03/04/what-is-context-window-in-large-language-models-llms/
39 https://www.ibm.com/think/topics/context-window
Training
The training phase of an LLM involves the updating of the parameters of the model based on the embeddings that are provided as input. This process is repeated until the entire training dataset is exhausted. At each layer of the neural network a calculation is performed and based on the purpose of the layer information can be passed back to the previous layers or the next layer receives the output from that completed layer. This propagation of information results in the adjustment of the relative weights captured by each parameter of the model. In some of the larger models, this could be billions of parameters, thus making this computationally very expensive to train such a model when the training set consists of trillions of tokens.
The neural network can gauge its accuracy through its loss function which is a mathematical function to determine the inconsistency between the predicted output versus the expected output.40 In other words it is possible to predict how accurate the current model being trained is at predicting the next token given the last input. If the model was trained using “This is a string of reworded tokens”, then the loss function will use “This is a string of reworded” and ask the model to predict the next token. If the next predicted value translates to “tokens” then the error rate is 0. Any other value will result in a value that represents how “inconsistent” the model guess was. The further the number is from 0 the greater the loss. This could mean that another round of training on the same data is required and/or a larger body of training data is required in addition.
Ideally the model should get close to 0 but never zero as that would represent overfitting and this is considered a weakness.41 Overfitting results where the training data matches the test data perfectly and gives a false sense of accuracy, but when tested against real data the model will fail to measure up to expectation.
Summary
The pre-training step of an LLM involves several important steps. This includes collecting and preparing the training data by filtering out unwanted content, designing a neural network architecture that yields desirable properties and performance. This requires several iterations and tweaking of hyperparameters and measuring the loss function to ensure that the trained model performs well on real data.
In the next blog post we will examine the base model and post-training activities to improve and customize the LLM.