
Part 4 - Forging forward with GenAI


Wicus Ross
Senior Security Researcher
Introduction
Welcome to the next part of our extended blog series on GenAI. In this blog post we continue working through the steps that are involved in creating a large language model (LLM). In the previous blog post we covered the pre-training steps where we looked at data collection and data preparation, tokenization and embeddings, and finally we touched on neural networks. Continuing from that we will conclude by examining the output of the pre-training step, namely the base model, and what the post-train process entails.
Please note that this blog series gives a high-level overview of the steps involved and is not intended as a ‘how to’ series. Ideally these blog posts will provide you with a starting point that enables you to continue your education. Please visit the supplied references for more details and keep those handy for future reference.
If you have not yet read the previous blog posts or wish to refresh your memory then please see part 1, part 2, and part 3 for more information. Part 3 covers the pre-training step that is crucial in producing an LLM and precedes this blog post.
Base models
A base model is the output of the completion of the pre-training step, which we cover in part 3 of this blog series. Think of a base model as a text simulator that “memorized” the training data and can generate output based on its ability to guess the next word in a sequence of text. The size of the model is a combination of the model’s architecture and how the deep neural network is designed. This is typically measured in numbers of parameters, where modern LLMs can easily have billions of parameters or weights. Parameters and weights are sometimes used interchangeably.
A base model is represented by a collection of files that define the configuration of the model’s neural network architecture, hyperparameters, metadata files, tokenizer and vocabulary mapping, and very importantly the model weights.1 The model weights can be very large and is normally split over several files that can be multiple gigabytes in size. For example, Meta’s Llama 4 Scout 17B 16E with 17 billion parameters has a file size of approximately 216 gigabytes.2
One of the first publicly available and open-weight transformer base models was GPT-2 by OpenAI.3 This model is rather raw and basic compared to modern base models. Each prompt required examples of the desired output and GPT-2 would then attempt to mimic the pattern to produce output. A slight variation on this is to let the GPT-2 write a paragraph or two based on a prompt, this effectively show cases the model’s nature at guessing what the next token/word will be.4 Back in 2019 this was a breakthrough and very exciting for researchers, however the practical use case beyond that was limited. Today a base model can produce hundreds of words in seconds and respond to more complicated prompts. Since then, several benchmarking and evaluation processes have been developed to gauge how well a model will respond in certain scenarios.
Evaluating and testing
Normally the creator of the model publishes a model card and optionally a paper that describes the LLM and its notable features and intended use cases.5 This includes an overview of the pre-training phase to define the constituent parts of the model.
Additionally, the model is evaluated against several well-defined benchmarks that test specific capabilities such as language, mathematics, reasoning, programming, and how well the model follows instructions. Certain metrics are recorded and then used to compile an overall score that can be used to compare other models’ performance.6
Examples of metrics include:
- Accuracy, sensitivity or recall, that is used to calculate the F1 score.
- Exact match
- Perplexity that measures prediction accuracy.
- Bilingual evaluation understanding
- Text summarization capabilities called Recall-Oriented Understand for Gisting Evaluation (ROGUE).
As with anything these metrics are limited and can be manipulated by training the model to perform well against those specific tests. This can result in overfitting as the LLM would perfectly “memorize” the response to a question. Although the benchmark metrics will be exceptional, performance with real world use cases could possibly fall flat.
The benchmarks will have to keep up with the pace of LLM advancement to measure capabilities that push the LLM to its limits. This requires the benchmarks to task the LLM with a broad range of challenges that also evaluates the expertise or specialized knowledge.
Examples of benchmarks include, but are not limited to:
- HellaSwag 7 8
- ARC (AI2 Reasoning Challenge)9
- TruthfulQA to test hallucination, in other words how likely the LLM would make up facts and present the information as true10
- GSM8K is a math evaluation test 11
- HumanEval examines coding capabilities 12
- SimpleBench 13
- GPQA by Google 14
- MLE Bench by OpenAI 15
SimpleBench is a newer evaluation of LLMs and is a multiple-choice text benchmark that ranks LLMs against humans. To put this into perspective, the human base-line score is 83.7% and at the start of April 2025 the closest model score was 51.6% for a state-of-the-art reasoning model.
Leaderboards such as lmarena.ai are fun to follow but should not be used to completely gauge a model’s capability as some of these leaderboards are based on community sentiment.16 A diverse leaderboard such as livebench.ai allows users to compare models based on various benchmarks.17
Also, such leaderboards tend to publish rankings for highly tuned and optimized models in addition to base models. The finetuned models do generally perform better than the root base model in most benchmarks. When evaluating a model consider multiple benchmarks and multiple reviews to get
5 https://arxiv.org/pdf/1810.03993
6 https://www.ibm.com/think/topics/llm-benchmarks
7 https://rowanzellers.com/hellaswag/
8 https://arxiv.org/abs/1905.07830
9 https://leaderboard.allenai.org/arc/submissions/public
10 https://arxiv.org/abs/2109.07958
11 https://arxiv.org/abs/2110.14168
12 https://arxiv.org/abs/2107.03374
13 https://simple-bench.com/
14 https://arxiv.org/abs/2311.12022
15 https://openai.com/index/mle-bench/
16 https://lmarena.ai/?leaderboard
17 https://livebench.ai/
Inference
We have already alluded to inference earlier when we mentioned prompt completion. Inference is basically “running the model” by providing a prompt for completion by the model. 18
The inference process (test-time compute) is distinct from the training process (train-time compute). A lot of effort is spent to optimize the inference process as this is where users of the model spend most of their time waiting for the next token of output to be generated.19 The faster the inference process, the less latency is inserted into the response generation.
Quantization
Quantization is the process to reduce the runtime memory and storage size requirements, where the former is much more desirable as runtime memory is a premium.
The parameter type of a model influences the amount of runtime memory and storage space a model consumes, as well as the speed and accuracy of a model. In simple terms an LLM is a large data structure where each element is a numeric value. This numeric value is typically a real number or fraction between 0 and 1. In computer terms this is represented by a floating-point (FP) value. It is also possible to use integer (INT) values to represent these parameters.
Under the hood the following technical variations are currently possible for training pre-trained models 20:
- FP32 – full precision 4 bytes or a 32-bit floating-point value, with the most precision but consumes the most resources.
- FP16 – half precision 2 bytes or a 16-bit floating-point value that has good precision and uses half the space of FP32.
- BF16 – half precision 2 bytes, but with larger exponent and smaller fraction.
BF16 is a common type as it offers a good balance for memory consumption, speed, and accuracy.
Additional efficiency gains can be obtained while finetuning a model by using:
- 4NF – 4-bit NormalFloat is a special representation for the least commonly used parameters, while the most used parameters remain in the BF16 representation 21 22
- INT8 – 1 byte or 8 bits that represents values between 0 and 255, or between -127 and 127 23
4NF and INT8 are used to reduce the size of the model to run on less expensive hardware or consumer grade hardware, but at the cost of accuracy.
Post-training
A base model must be finetuned to make it suitable for a specific use case, for example a “chat” assistant. This requires approaches to introduce examples of how the model must behave when a given prompt is presented. Using a large body of example request-response pairs the model can be infused with desirable behavior. Synthetic test data can be created by specially trained neural networks that can judge the performance of the LLM and assign a score to that response that is used to correct the model. Techniques such as reinforcement learning allow researchers to scale the training process without relying on a human to evaluate hundreds of thousands of interactions. Similarly, the models can be trained to acknowledge limitations and not generate a fake response just to please the user.
Supervised finetuning
Supervised finetuning (SFT) can be thought of as a way to focus an LLM to behave in a predetermined manner. A base model is adjusted based on example prompts with desired responses. This is a new training run that uses additional content, the conversations between the user and the AI assistant. The conversations are generated by human experts that seed the training data with a wide range of topics.24 This process is very dependent on the ability of humans to provide example conversations that meet specific requirements.
Most SFT datasets are proprietary and expensive to produce, thus these are not generally shared. There are example datasets that can be used for fine-tuning a base-model and these could serve as a starting point to expand the dataset.25 26 Be aware that these open datasets must be evaluated as the conversations in these datasets can insert unwanted side effects.
24 https://arxiv.org/pdf/2203.02155
25 https://huggingface.co/datasets/OpenAssistant/oasst1
26 https://github.com/thunlp/UltraChat
Hallucination and alignment
A hallucination is when LLMs generate an incorrect response to a question, instead of stating that it does not know the answer. The “conversations” used in the post-training serve as a template that the LLM imitates when it is executed during the inference process when a real-world user asks a question. If there are enough examples, then the quality of the response will be desirable. Because an LLM “guesses” the next tokens based on the input there is a chance that the LLM will fabricate a response that could be false.
It is possible to reduce the potential for hallucination by providing examples of responses to questions where the LLM does not have a factual or appropriate response. This could be tied to the knowledge cutoff of the LLM. For example, the training data may not have examples of current news events. During the SFT step the prompt engineer gives an example prompt that would result in a “I do not know” answer. This “teaches” the LLM that it can admit that it does not know instead of manufacturing factually inaccurate statements.
Another more scalable approach is to extract snippets from the pre-training data and ask the model to respond to a question about the snippets. The response is then scored by a purpose-built platform or another LLM that was trained on the questions and answers. This produces a feedback loop that can be used to lower the model’s tendency to hallucinate. 27 28
Similarly, a model can be trained to recognize prompts that are potentially harmful, malicious, contains hate speech, racism, relates to unlawful activity, etc. Example prompts containing prompts with this kind of requests or instructions could be given with a desired response such as “I’m unable to respond to this request”. This speaks to alignment or steering by the party expanding the model during the SFT or subsequent phases.
27 Grattafiori et al., The Llama 3 Herd of Models, 2024, pages 26-27 https://arxiv.org/pdf/2407.21783
28 https://arxiv.org/html/2407.17468v1
Reinforcement learning
Reinforcement learning is a process to further train an LLM using a reward system to encourage the model to seek various paths for a specific result. A model is given a prompt with an easy verifiable answer and there is only one answer to the question, for example a math question. The model must then generate a response that explains how the specified answer is reached. Another process judges the responses and scores the answer. This process is repeated to select the best answers that is then used to adjust the model’s parameters, and the process is repeated, ultimately leading to well structured and contextually appropriate output. 29
The reinforcement process can be designed to be a scalable process by starting off with a template that can be used to generate a large body of training data. The associated reward scoring system is a steering or aligning mechanism that encourages emergent properties of the model.
Reinforcement learning with human feedback
This can be considered a finetuning approach of an LLM and may on the surface closely resemble plain reinforcement learning. Reinforcement learning with human feedback (RLHF) was developed to provide a scalable improvement for domains where the answers or responses to a prompt are nuanced and subjective to human judgement and tastes.30 RLHF can be expensive, as the process of compiling the training set requires high-quality preference data that is evaluated by experts.31
Like with normal reinforcement learning, a judge is created that simulates a human for a specific domain, for example creative writing. This judge can be a specific neural network that is trained to simulate how humans would score or rank a particular piece of text based on a given prompt. Several human experts in the respective domain then provide their feedback which is used to train the model that will be used to judge the creative writing skills of an LLM.
With the judge trained the LLM is provided with the prompts known to the judge, for example the creative writing prompts used to train the “judge model”. The LLM under scrutiny produces a response and the judge model scores the output. The score is then used to adjust the LLM’s parameters accordingly. If the reward score is low, then the identified parameters are adjusted to reduce the likelihood of producing a similar output. If the reward score is high, then the respective parameters of the LLM are adjusted to encourage the likelihood of a similar response in the future.
According to Andrej Karpathy RHLF has some implications to consider, namely the up- and downsides.32 The upside is that it is easy for human experts to participate in creating the training dataset of the judge model in what Andrej describes as the discriminator vs generator gap. It is easier for a human to rank or score (discriminate) something such as text than generating a similar piece of text to match a specific requirement. The downside of RLHF is that it is still a neural network that is a statistic approximation or simulation of a human expert in that it may fail to come close to a human in certain aspects. For example, the judge can score something high that may be nonsensical to humans.
When training an LLM using RLHF it is best to let the training iteration run for a short period, as it has been found that prolonging the RLHF training step can result in the output of the LLM resulting in much poorer quality of responses.
Thinking models
A “thinking model” in the context of generative artificial intelligence (GenAI) is a conceptual label that refers to the prompting techniques used by an LLM to break down a user prompt into simpler steps. The simpler steps are then evaluated and summarized, and the combination of these summaries are used to compile the final output. It is fascinating to observe this process as an LLM seems to have an internal monologue.33 These thinking models are similarly trained to how reinforcement learning with human feedback models (RLHF) are trained.34 35
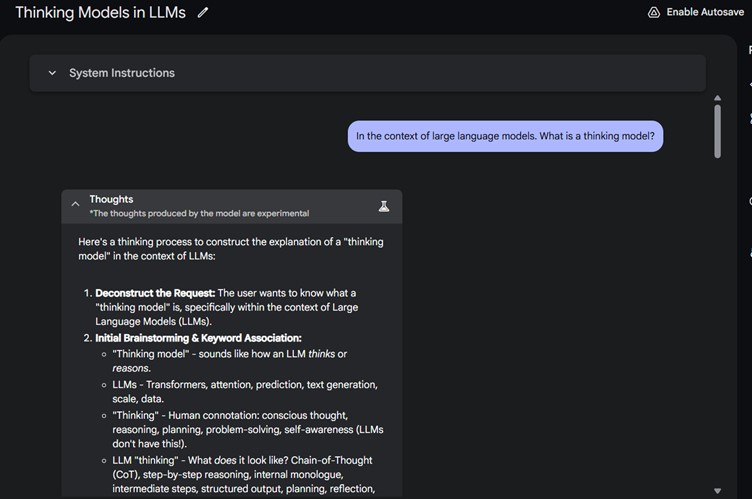
The chain of thought (CoT) process that compiles the individual steps seems like the LLM is planning its answer as well as testing its hypothesis or assumptions. In some cases, it can lead to the LLM identifying mistakes that it can self-correct. This approach helps for transparency of the LLMs and can be reviewed by a human for correctness. There are also claims that this approach reduces hallucinations as the LLM can test its answers by attempting more than one path before reaching its conclusion.
Thinking models are good at examining complex questions that are broad and may require multiple facts or hypotheses to answer. Thinking models take longer to respond to a prompt as it generates additional information as part of its output generation process. The time it takes can be tens of seconds more than a “non-thinking” model.
Anthropic refers to thinking models as simulated reasoning (SR). Anthropic published research in which they discovered that the SR models fail to disclose their “reasoning” steps.36 It is important to keep in mind that LLMs do not think like humans and are a combination of algorithms and mathematics that produce output simulating human language.
33 The content in this section was generated with help from Google Gemini 2.5 Pro Preview O3-25.
34 https://medium.com/@sebuzdugan/thinking-llms-general-instruction-following-with-thought-generation-paper-explained-7cefb01edded
35 https://arxiv.org/html/2410.10630v1
36 https://arstechnica.com/ai/2025/04/researchers-concerned-to-find-ai-models-hiding-their-true-reasoning-processes/
Summary
Producing an LLM from scratch requires many resources and skilled experts. The pre-training step involves taking volumes of curated and cleaned data that is prepared based on the architecture of the deep neural network. The transformer architecture is a popular neural network design and requires that the training data is tokenized and then converted into an embedding. The neural network is configured by specifying hundreds of hyperparameters that influence the characteristics of a model.
State-of-the-art LLMs can be very large and consume a lot of resources, especially memory of the dedicated hardware. The richness of neural networks is dictated by the number of parameters or weights and is currently measured in billions of parameters. Techniques such as quantization can be used to reduce the size of the model as well as improve performance, but this comes at the expense of accuracy and utility.
The pre-training step produces a base model that for all purposes is a foundation and rarely used by itself, except for evaluating capabilities and features. These base models are steered using techniques such as supervised finetuning (SFT), reinforcement learning (RL), or reinforcement learning with human feedback (RLHF). SFT can be very useful to induce certain capabilities as well as eliminate unwanted behavior. RL and RLHF are used to further improve a base model or a SFT model. RL and RLHF are scalable and use other neural networks to assess or score the performance of the LLM. The scores are used to correct the LLM.
Thinking models are a newer kind of LLM that exhibits chain of thought (CoT) where the LLM breaks down a prompt into smaller steps. The combined output of each step is summarized into a final output. CoT allows the thinking model to test multiple hypotheses or solutions to determine whether its conclusion is correct.
New algorithms and techniques are being developed to produce generative artificial intelligence with desirable attributes. The rush towards an LLM that matches a human’s cognitive capability, also referred to as artificial general intelligence (AGI), is fueling innovation as well. Budgetary and physical constraints such as lack of adequate hardware will contribute to new approaches that will enable what was once only dreamt of.